未完待续
CPU
2.负载均衡
- watch -d 高亮
- uptime : 平均负载(平均活跃进程数)
- 查看cpu数量(注意逻辑cpu,物理cpu区别)
-
grep ‘model name’ /proc/cpuinfo wc -l - lscpu
-
- linux压力测试: stress –cpu 1 (升级版: stress-ng)
- 性能监测: sysstat(包)
- mpstat -P ALL 5 多核cpu监测
- pidstat -u 5 1 进程监测
3. CPU上下文切换1
- CPU上下文包括:
- CPU寄存器
- 程序计数器
- 上下文切换包括:
- 进程上下文切换
- 系统调用(进程内而非不同进程的切换),也叫特权模式切换。即进程空间在用户空间和内核空间的切换。实际会发生两次上下文切换。(这个系统调用说的有点模糊,还是不清楚是否应该归在这里)
- 每个CPU有维护队列,按优先级和等待时间排序
- 进程切换过程,发生于内核态,时间纳秒-毫秒
- 收到信号,挂起,记录当前进程的虚拟内存、栈等资源存储;
- 将这个进程在 CPU 中的上下文状态存储于起来;
- 然后在内存中检索下一个进程的上下文
- 并将其加载到 CPU的寄存器中恢复;
- 还需要刷新进程的虚拟内存和用户栈;
- 最后跳转到程序计数器所指向的位置,以恢复该进程。
- 时机
- 进程执行完毕
- 为了公平调度分配的时间片用完
- 资源不足(如内存)等待满足
- 程序sleep
- 优先级更高的进程
- 硬件中断
- 线程上下文切换
- 区别:线程是调度的基本单元,进程是资源拥有的基本单元
- 进程拥有多个线程时:
- 虚拟内存和全局变量切换时不需要保存
- 私有数据比如栈和寄存器,切换时需要保存
- 消耗的资源更少
- 中断上下文切换
- 进程上下文切换
4. CPU上下文切换2
- vmstat 5 性能分析,cs表示上下文中断, r表示队列长度
- pidstat -w 输出进程切换指标, -t线程
- cswch: 自愿上下文切换,包括io/内存不足等请求资源的问题
- nvcswch: 非自愿,高代表CPU瓶颈
- sysbench –threads=10 –max-time=300 threads run 模拟线程
- watch -d cat /proc/interrupts (proc文件系统代表内核空间和用户空间通信机制)
5-6. 某个CPU使用率100%

- top: 总体CPU内存,默认使用3s间隔计算平均。ps 显示每个进程的资源使用,从进程开始运行计算。
- pstree 查看进程间关系
- execsnoop 实时监控进程的exec()行为,实例中因为程序不断重启导致的高CPU,可以用这个方法发现短时应用
- 查找热点函数: perf top,record,report (-g开启调用, -p指定进程)
- 实例中结合pidstat和perf record -g -p xxx 查找热点函数
- 注意docker中依赖库在镜像中,需要在容器内查看结果,如下操作:
find | grep perf.data或 find / -name perf.data docker cp perf.data phpfpm:/tmp docker exec -i -t phpfpm bash cd /tmp/ apt-get update && apt-get install -y linux-perf linux-tools procps perf_4.9 report
```
- 注意docker中依赖库在镜像中,需要在容器内查看结果,如下操作:
7-8. 遇到僵尸进程
- top看进程的状态: R(Running), D(Disk sleep), Z(zombie), S(Interruptible sleep), I(Idle), T(stopped), t(Traced)
- dstat: 观察io和cpu
9-10. 软中断
- 硬中断
- 上半部用来快速处理中断, 主要处理和硬件相关或时间敏感的
- /proc/interrupts
- 软中断
- 下半部用来处理上班部未完成的,通常以内核线程方式运行
- /proc/softirqs ,不同列代表: 网络收发,定时,调度,RCU锁等
-
软中断内核线程: ps aux grep softirq (中括号代表无法获取命令行参数,一般代表内核线程)
11. 总结: 如何运用这些CPU相关的指标和命令
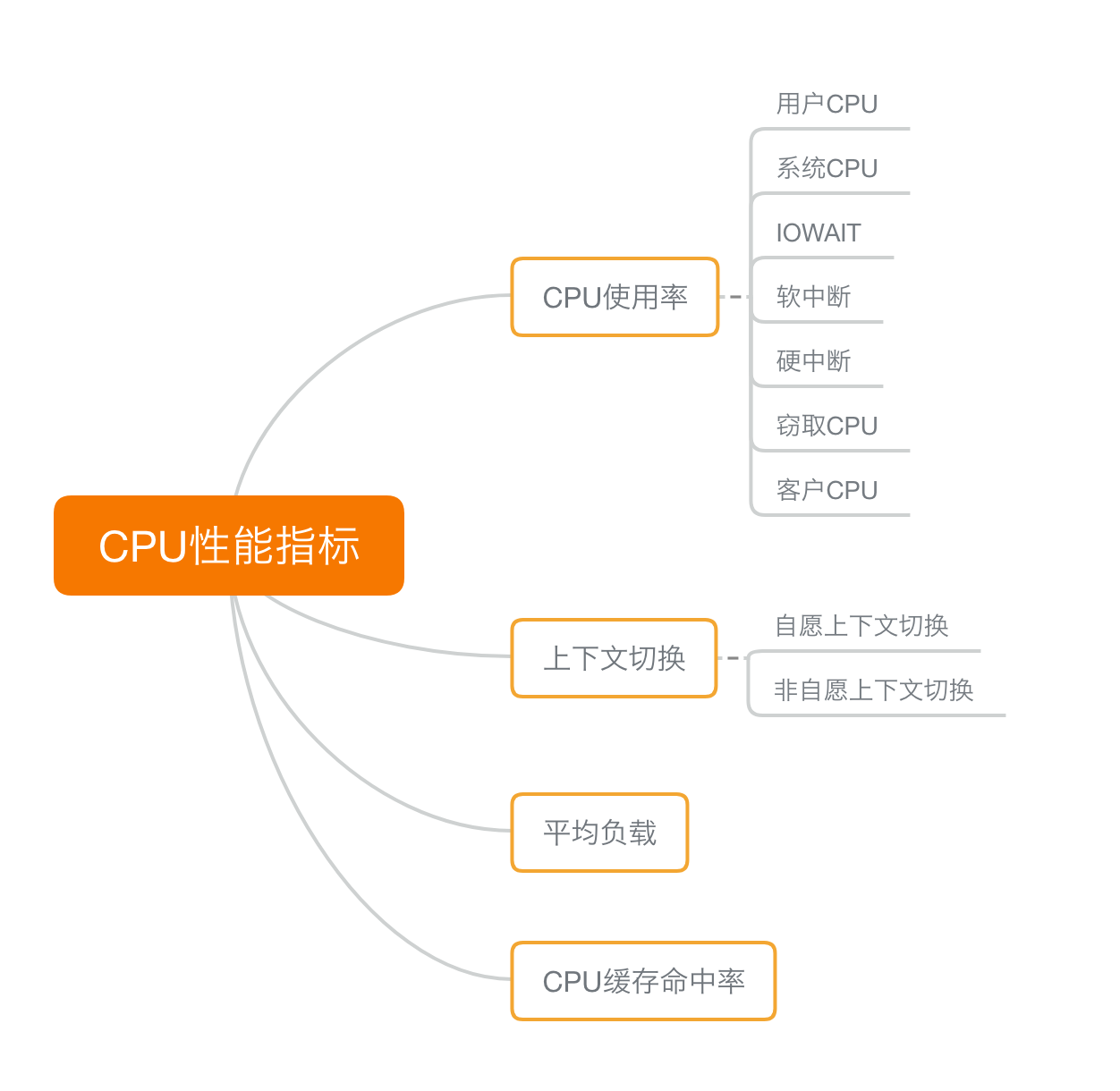
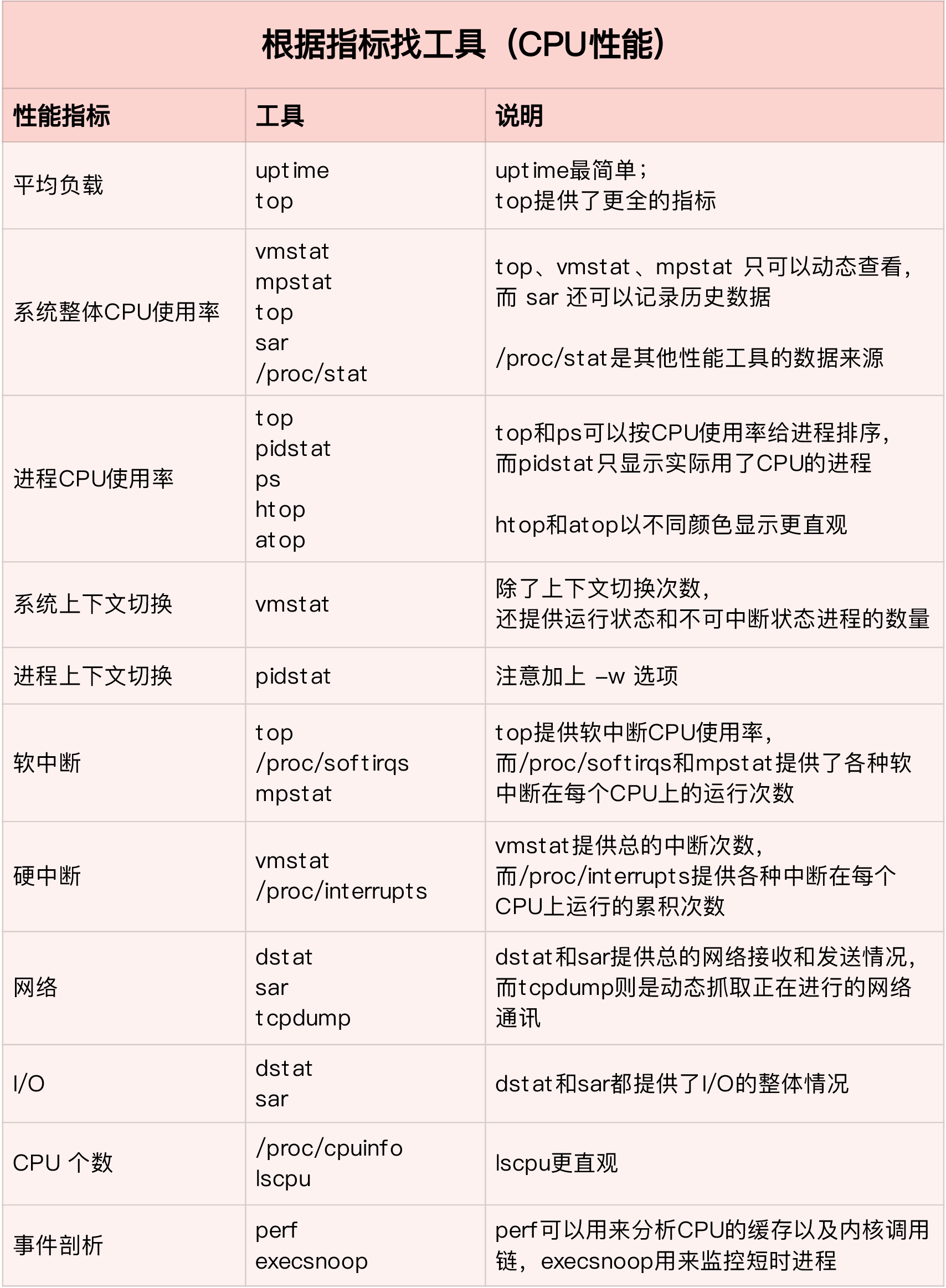
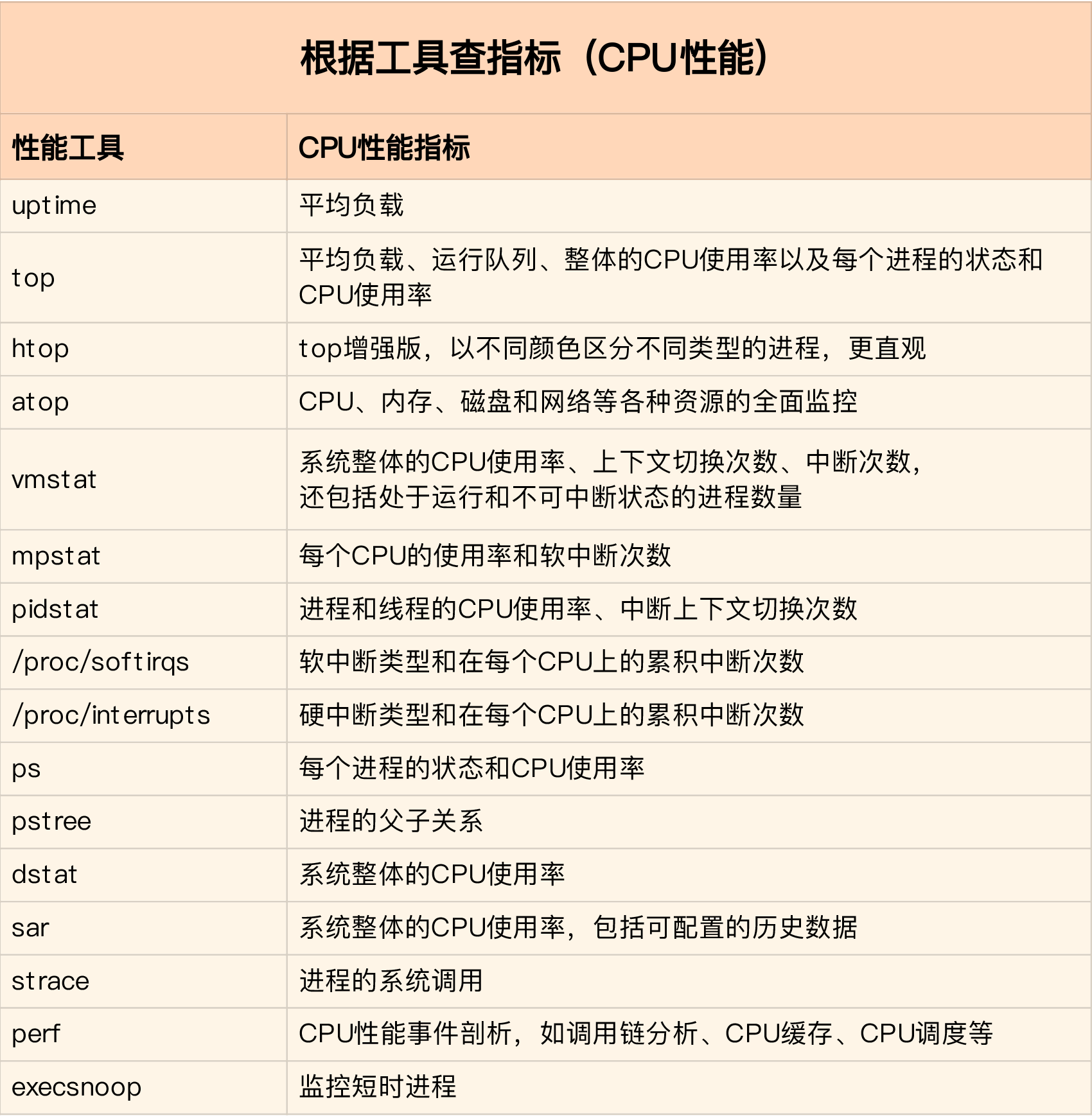
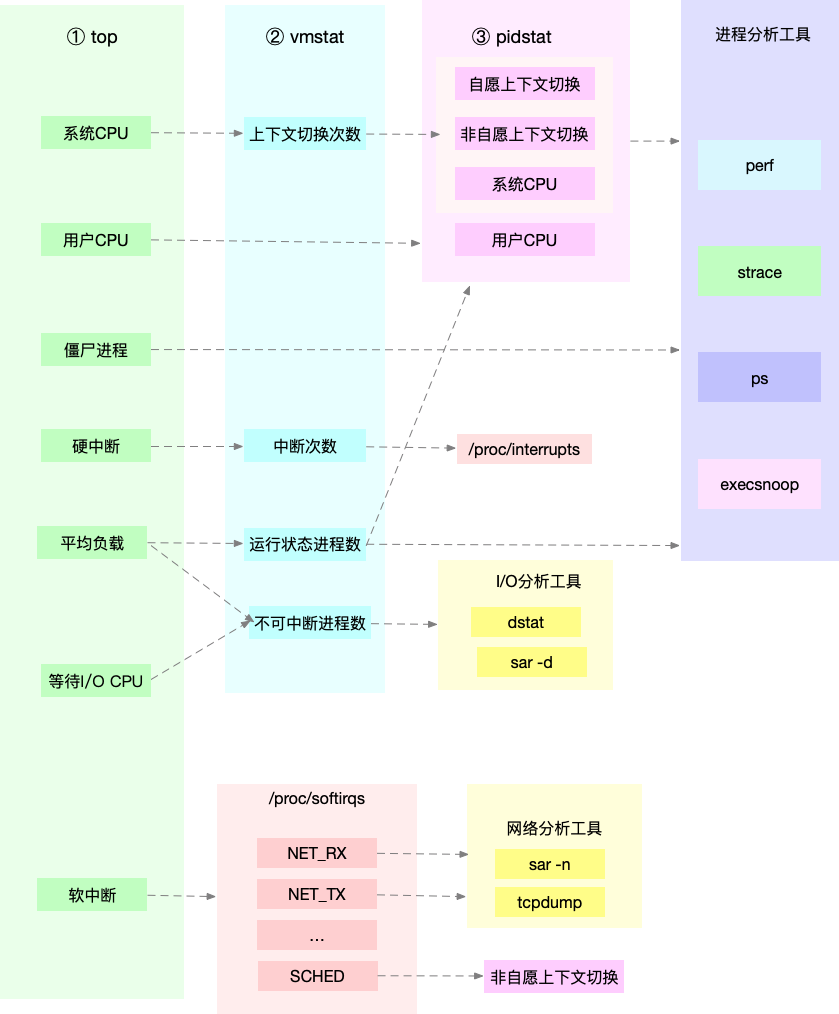
12. CPU优化思路
- 三大问题
- 如何评估性能优化效果
- 确定指标,测试优化前后的指标
- 选择多个维度,比如应用维度(吞吐)和系统维度(CPU使用率)
- 避免测试工具干扰性能(so使用两台机器),注意优化前后配置相同
- 多个性能问题同时存在如何优化
- 有多种方法时如何选择:
- 如何评估性能优化效果
- CPU优化
- 应用程序优化
- 编译器优化
- 算法优化
- 异步
- 多线程代替多进程
- 缓存
- 系统优化
- CPU绑定
- CPU独占
- 优先级调整(nice)
- 限制进程资源(Linux cgroups)
- NUMA: 让CPU只访问本地内存
- 中断负载均衡(irqbalance)
- 应用程序优化
- TIPS之,不要过早优化,不要一步到位
内存
15. Linux如何管理内存
- 内存映射,分配,回收(太复杂)
- free
- total: 总内存
- userd:已使用
- free:未使用
- shared:共享内存
- buff/cache: 缓存和缓冲区
- available:新进程可用的
- top (按M 切换到内存排序)
- VIRT: 虚拟内存
- RES:常驻内存
- SHR:共享内存
- %MEM:使用的物理内存占总内存百分比
16-17. buffer, cache
- 分开查看两个指标:
- cat /proc/meminfo
- 区别
- buffer: 对磁盘数据的缓存(裸IO) ; Buffers 是内核缓冲区用到的内存,对应的是 /proc/meminfo 中的 Buffers 值。
- cache: 对文件数据的缓存; Cache 是内核页缓存和 Slab 用到的内存,对应的是 /proc/meminfo 中的 Cached 与 SReclaimable 之和。
- 缓存命中率
- bcc-tools(centos安装复杂)
- cachestat: 系统缓存的读写命中
- cachetop: 每个进程的缓存命中
- pcstat: 文件在内存中的缓存大小
- strace -fp : 查看应用的系统调用
- bcc-tools(centos安装复杂)
- echo 3 > /proc/sys/vm/drop_caches ; 清空缓存
18. 内存泄漏
- vmstat,free减少而buff,cache不变,可能泄漏
- memleak, bcc包中专门检测内存泄漏的
19-20. swap
- 内存资源紧张时
- 杀死进程
- 内存回收
- 文件页:
+ 直接回收- 脏页(被应用修改过):先写入磁盘再回收
- 匿名页(堆内存): 使用Swap机制写入磁盘
- 文件页:
- 作用:把一块磁盘空间或本地文件当作内存来使用
- 通过/proc/sys/vm/swappiness调节回收文件页和匿名页的倾向
- NUMA架构,本地内存不够时,可以从其他Node寻找空闲内存
- smem –sort swap ,查看进程的swap使用情况
21. 内存总结
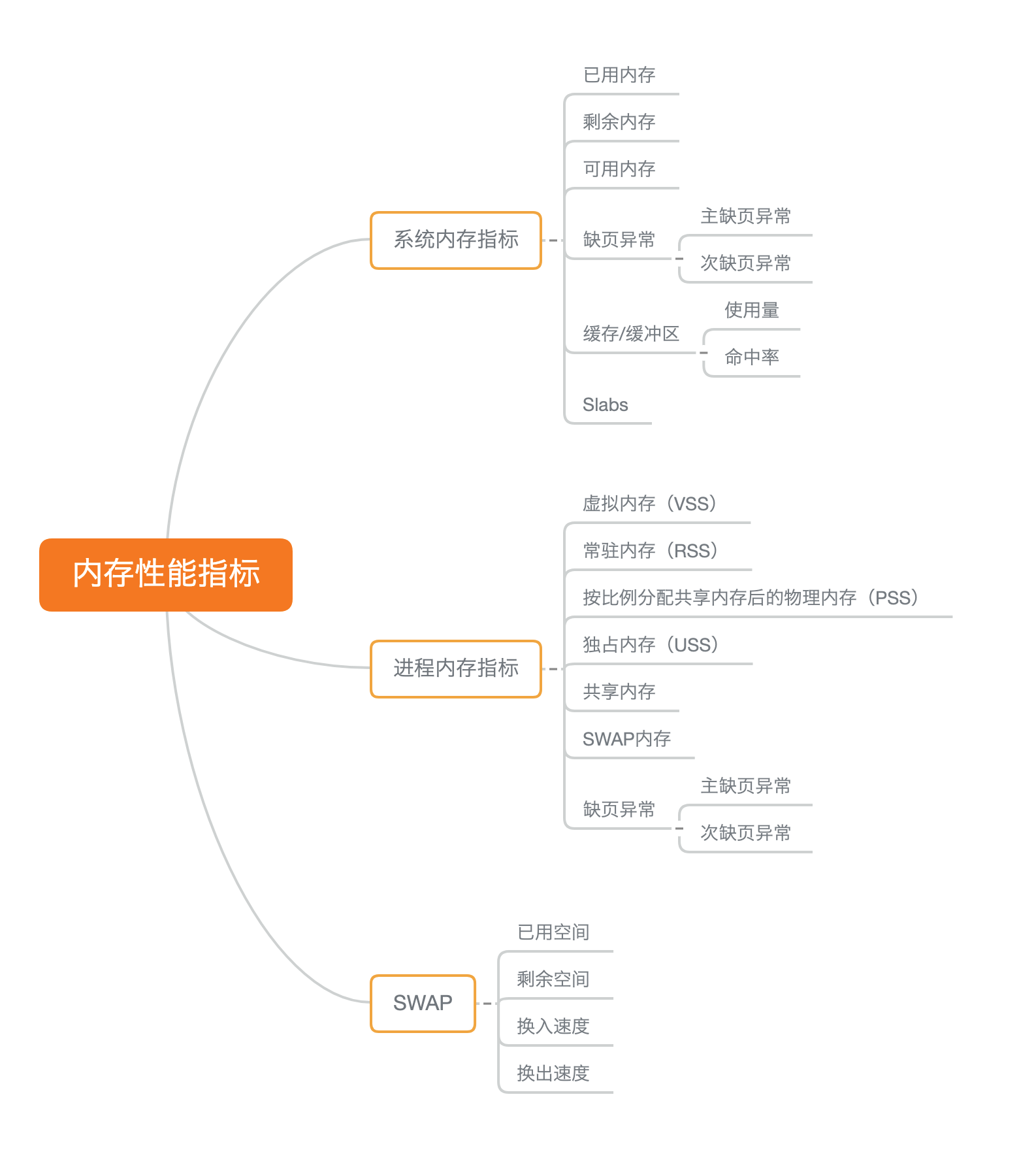
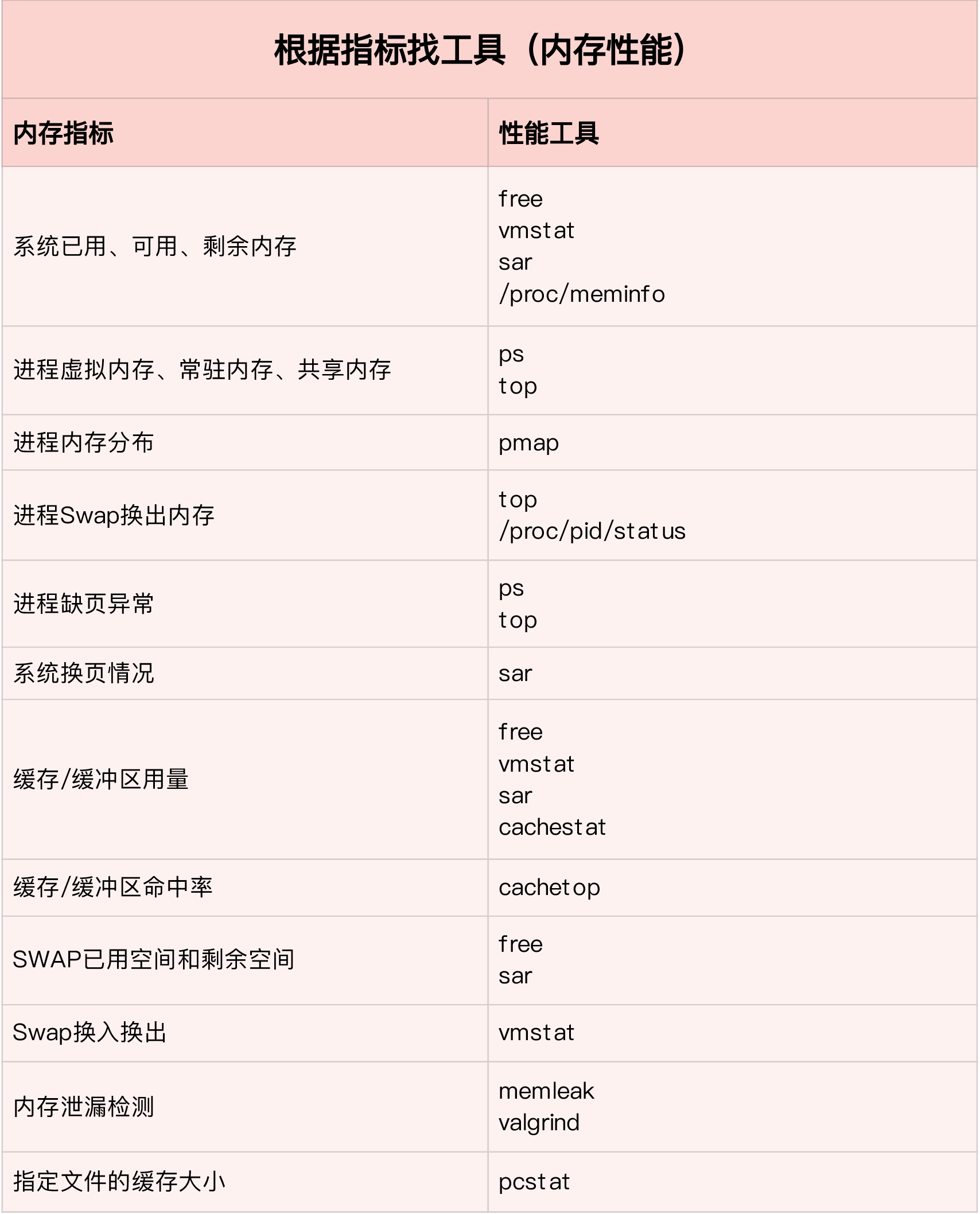
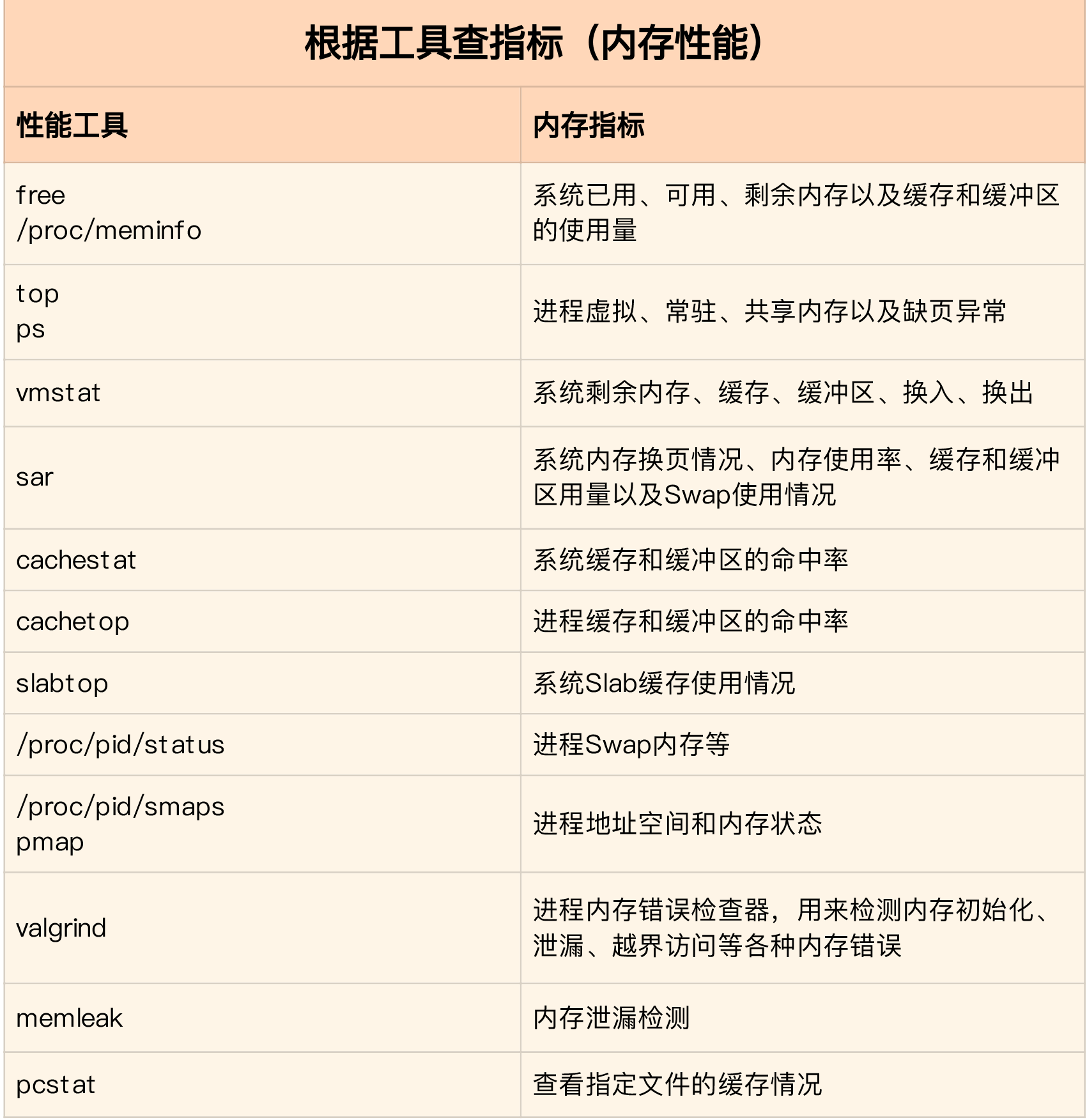
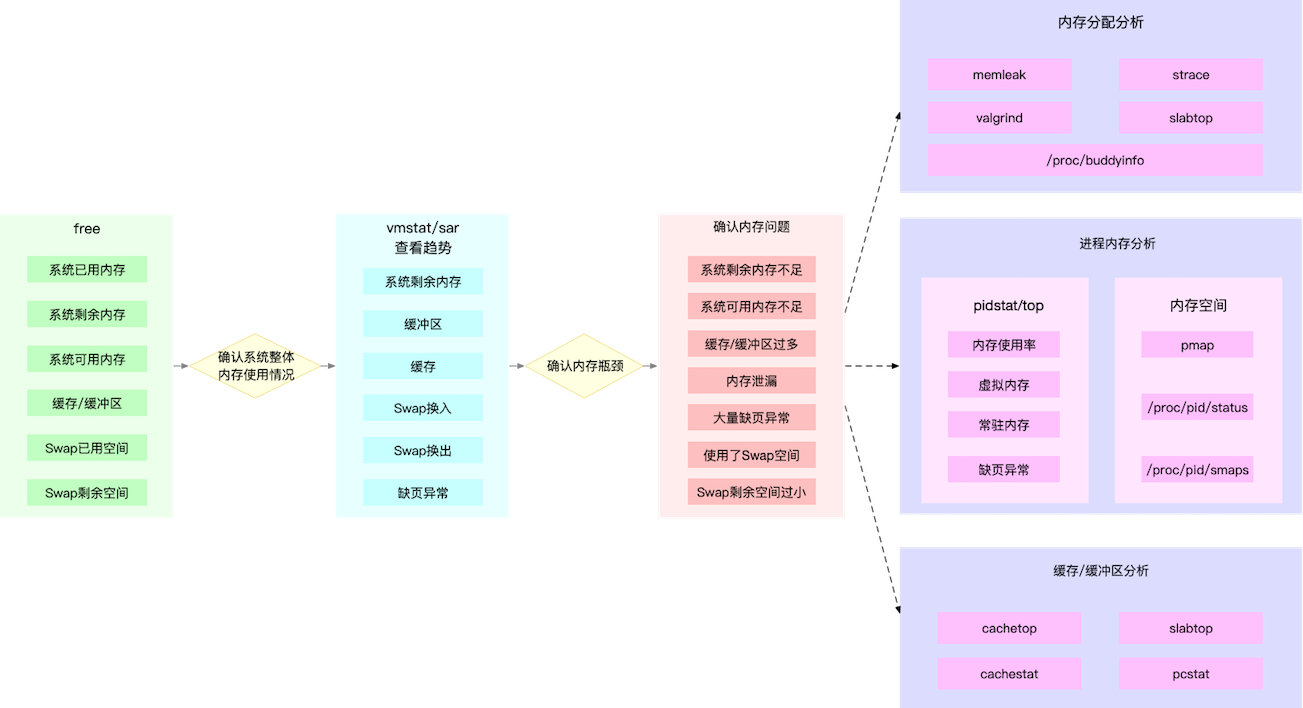
- 常见优化思路
- 禁止swap,降低swapness值
- 减少内存动态分配, 比如内存池,大页
- 尽量使用缓存和缓冲区访问数据
- cgroups等方式限制内存
- 调整oom_score防止被kill
文件系统和磁盘IO
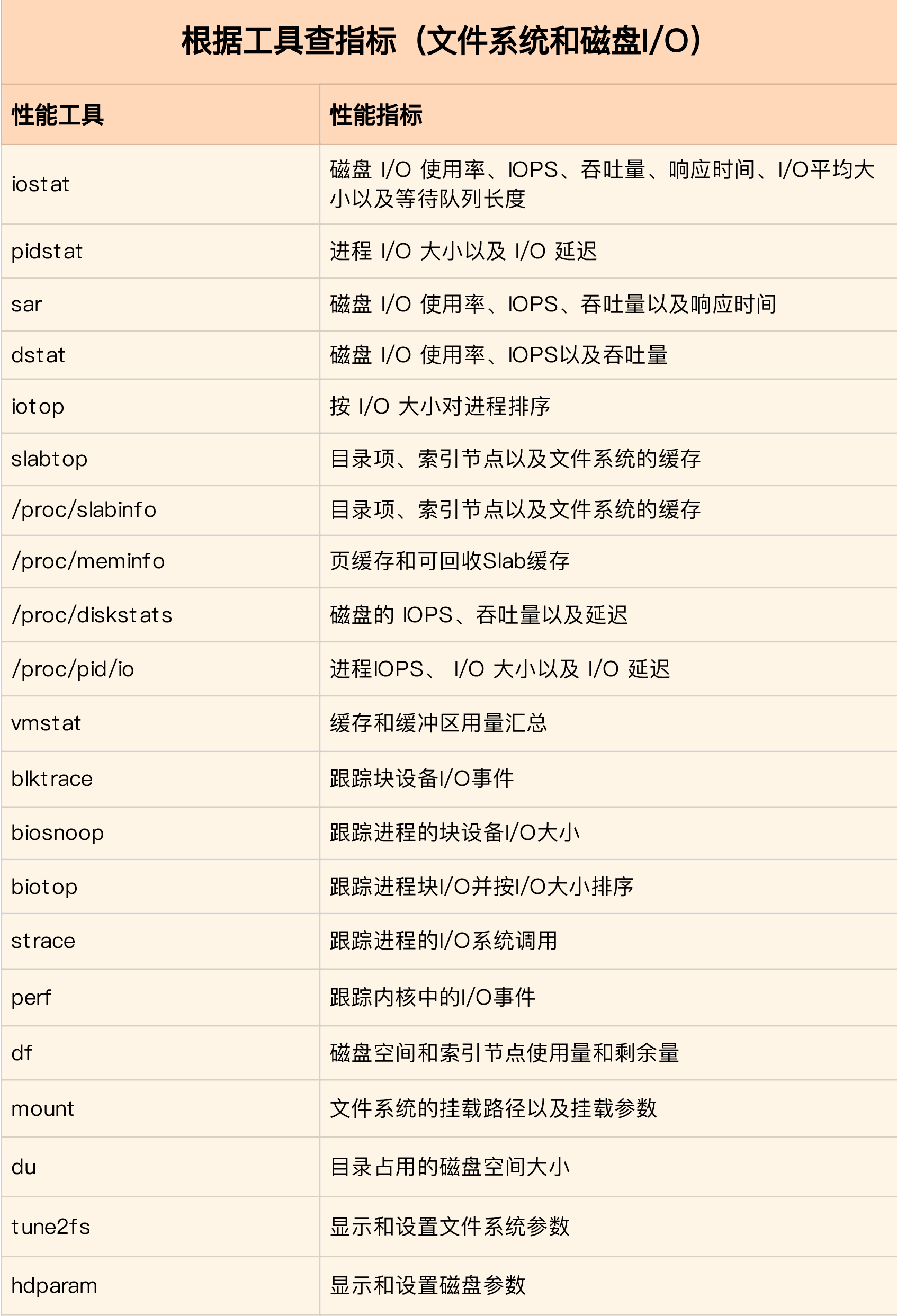
23. 文件系统基础
- linux中一切皆文件
- 每个文件分配的两种数据结构:
- 索引节点: 唯一标识,记录文件元数据
- 目录项(缓存),维护文件系统的树状结构
- 文件系统架构
- VFS: 虚拟文件系统,提供统一接口
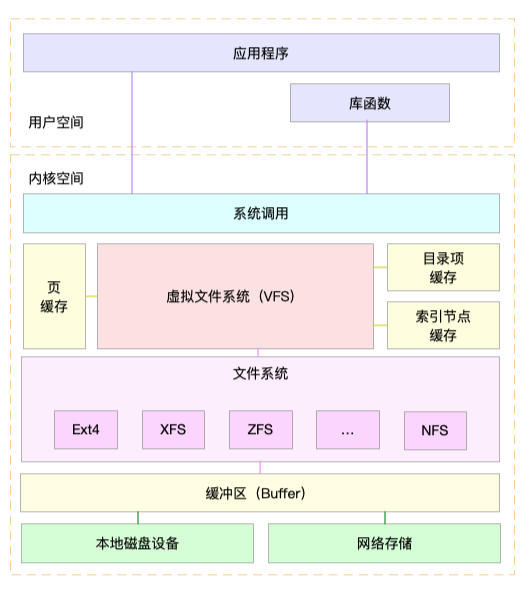
- 读写方式导致的IO分类: (非)缓冲IO,(非)直接IO,(非)阻塞IO, 同(异)步IO
- 容量 df -h, 索引节点容量: df -ih
- 缓存cache
- 页缓存
- slab, slabtop可监控
- 目录项缓存 dentry
- 索引节点缓存 incode_cache
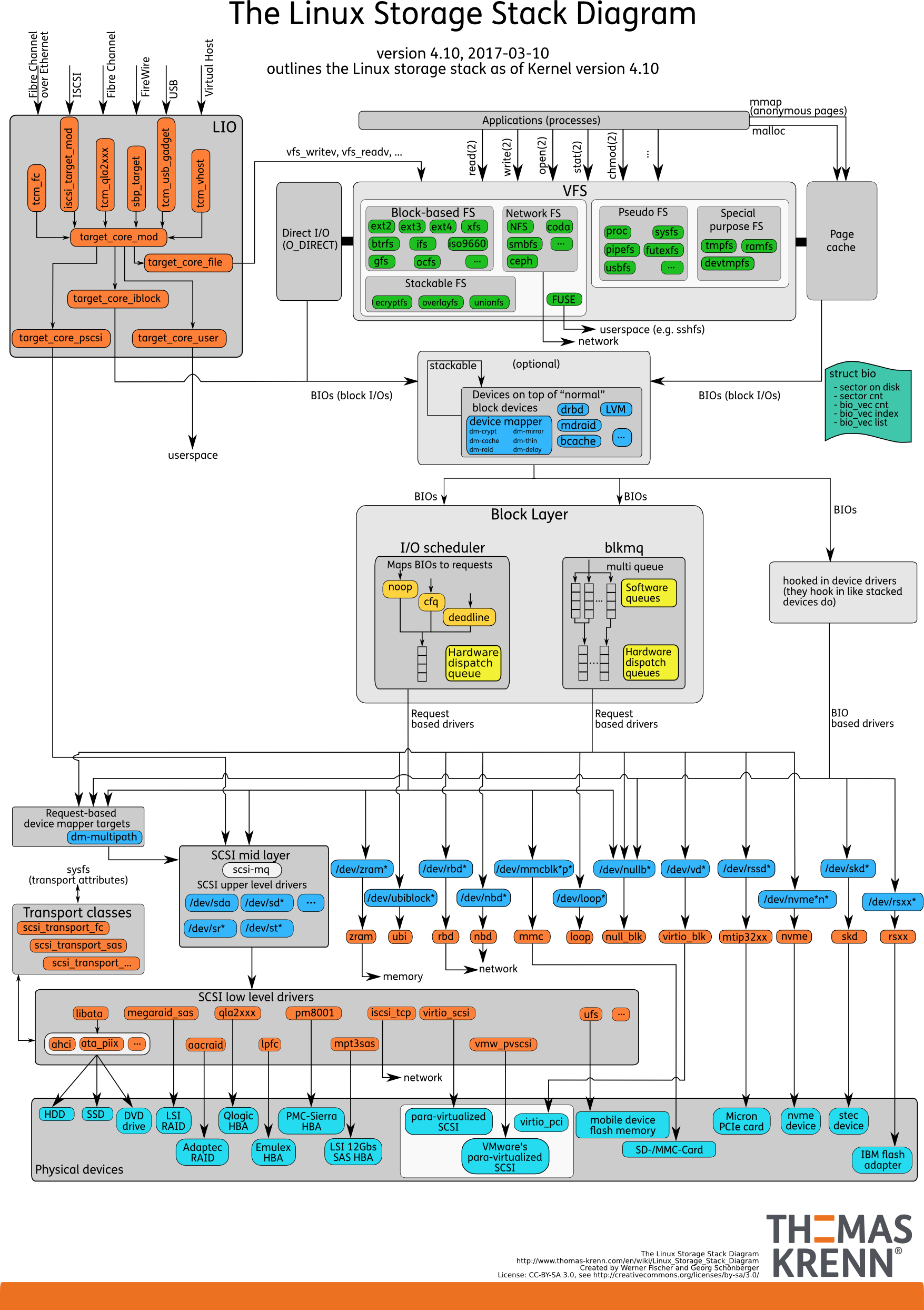
24. 磁盘IO
- IO栈
- 文件系统层
- 通用块层
- 设备层(驱动)
- IO栈全景图
- 磁盘
- 按介质分:
- 机械:最小读写单位512B, 随机IO需要磁道寻址
- 固态:最小读写单位4KB,8KB等
- 按接口分: IDE, SCSI, SAS, SATA(/dev/sda), FC
- RAID冗余独立磁盘列阵: 多块磁盘合成一个逻辑磁盘
- 按介质分:
- 通用块层作用
- 向上提供访问块设备接口;向下提供框架管理设备驱动
- IO请求调度:
- NONE: 无
- NOOP:先入先出
- CFQ: Completely Fair Schedular, 按时间片均匀分配
- Deadline: 多用于IO压力重的场景,如数据库
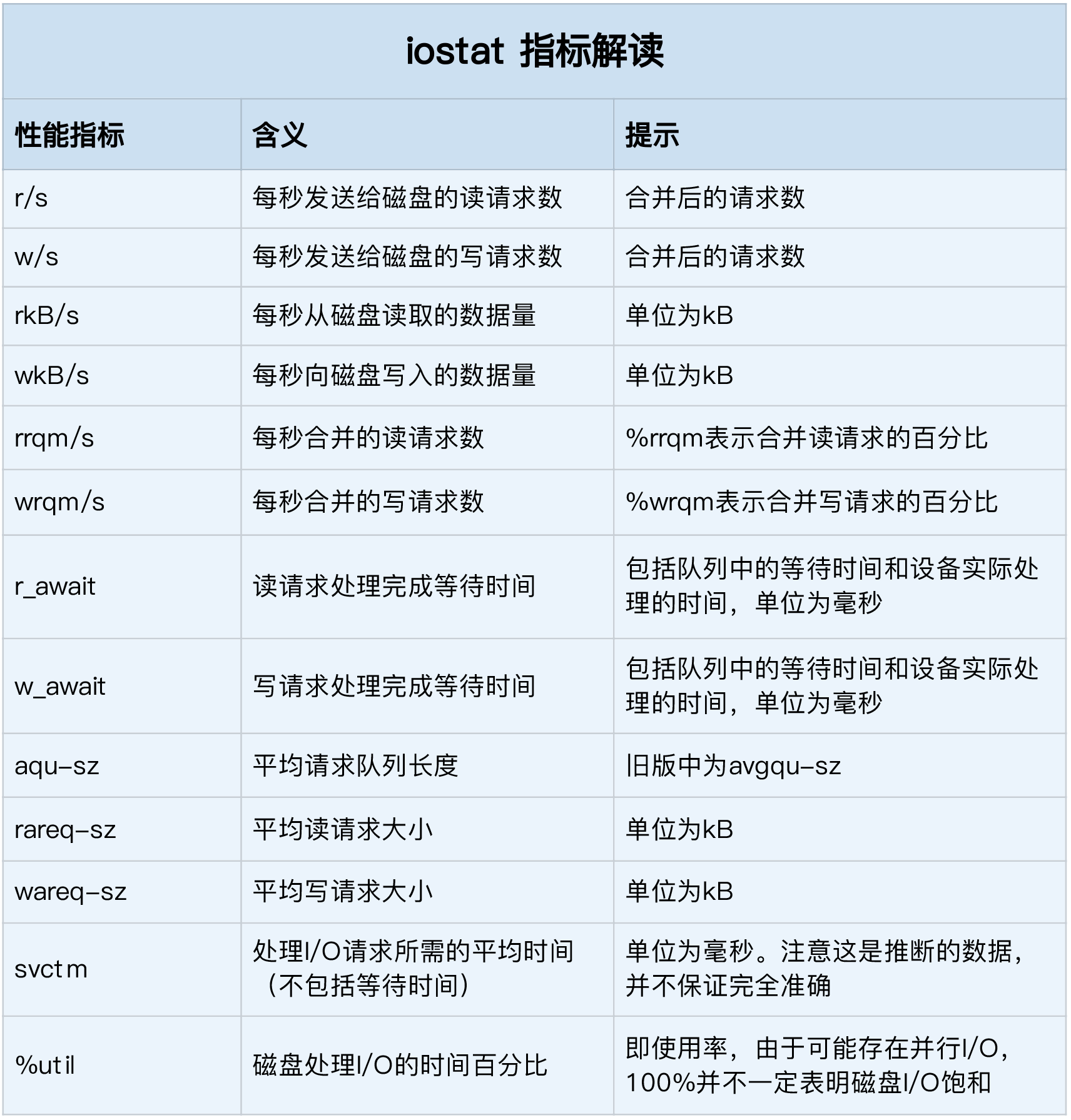
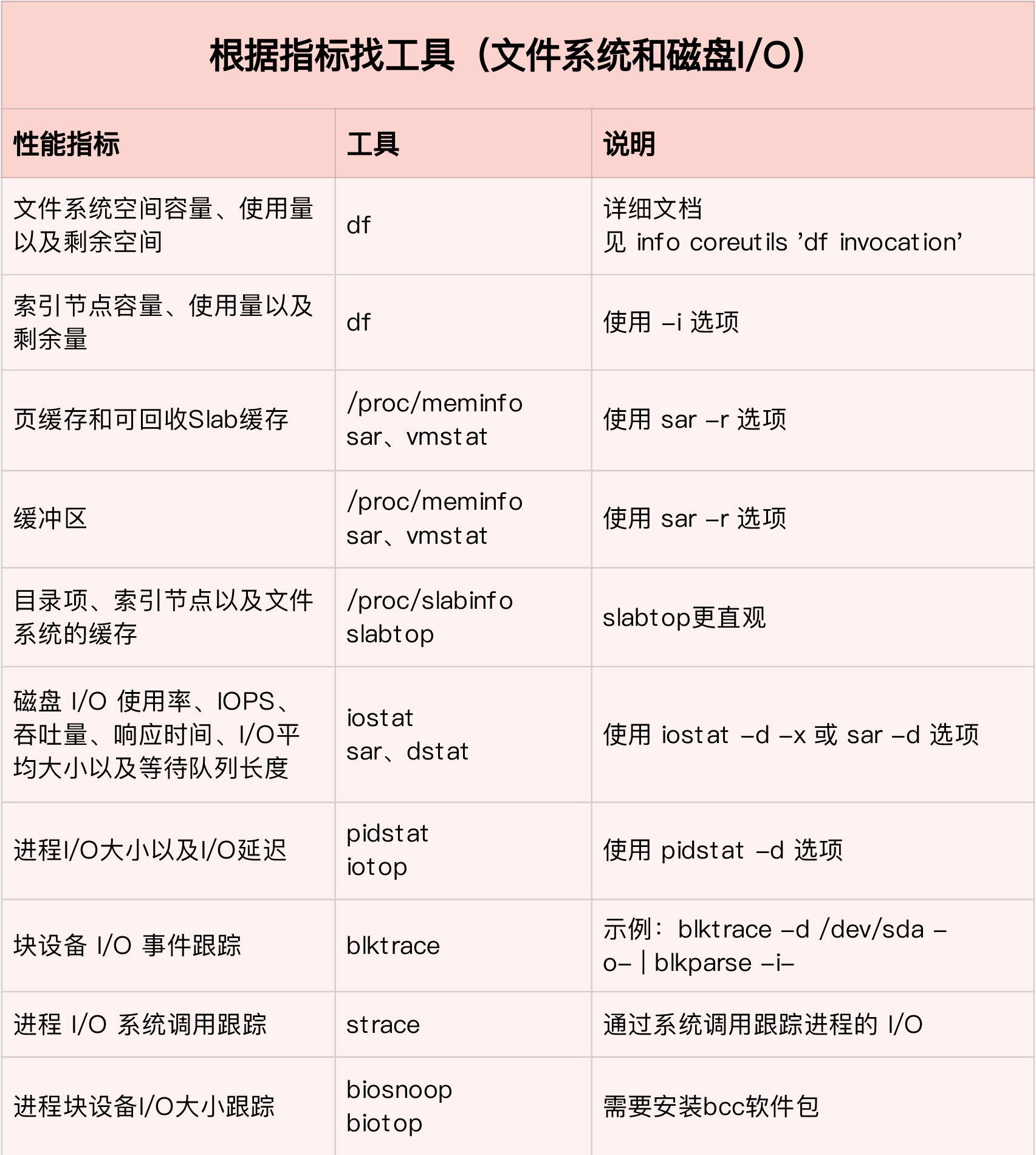
25-27. io指标
- IO性能基本指标, 以及对应的iostat结果
- 使用率, IO时间百分比,不考虑大小; %util
- 饱和度,繁忙程度,无法直接用iostat得出
- IOPS: i/o per second ; r/s + w/s
- 吞吐量 ; rkB/s + wkB/s
- 响应时间; r_await+w_await
- iostat -d -x 1
- pidstat -d 1
- iotop
- lsof -p 进程打开文件列表
- lsof -i:22 查看指定端口有哪些进程在使用
28-29. 实例
- top 发现wa即iowait高
- iostat -d -x 1 发现磁盘读取瓶颈
- pidstat -d 1 (-d表示io情况) 发现大量读取的进程并符合iostat的结果,由此找到进程
- 用lsof 和 strace看下进程具体在读什么
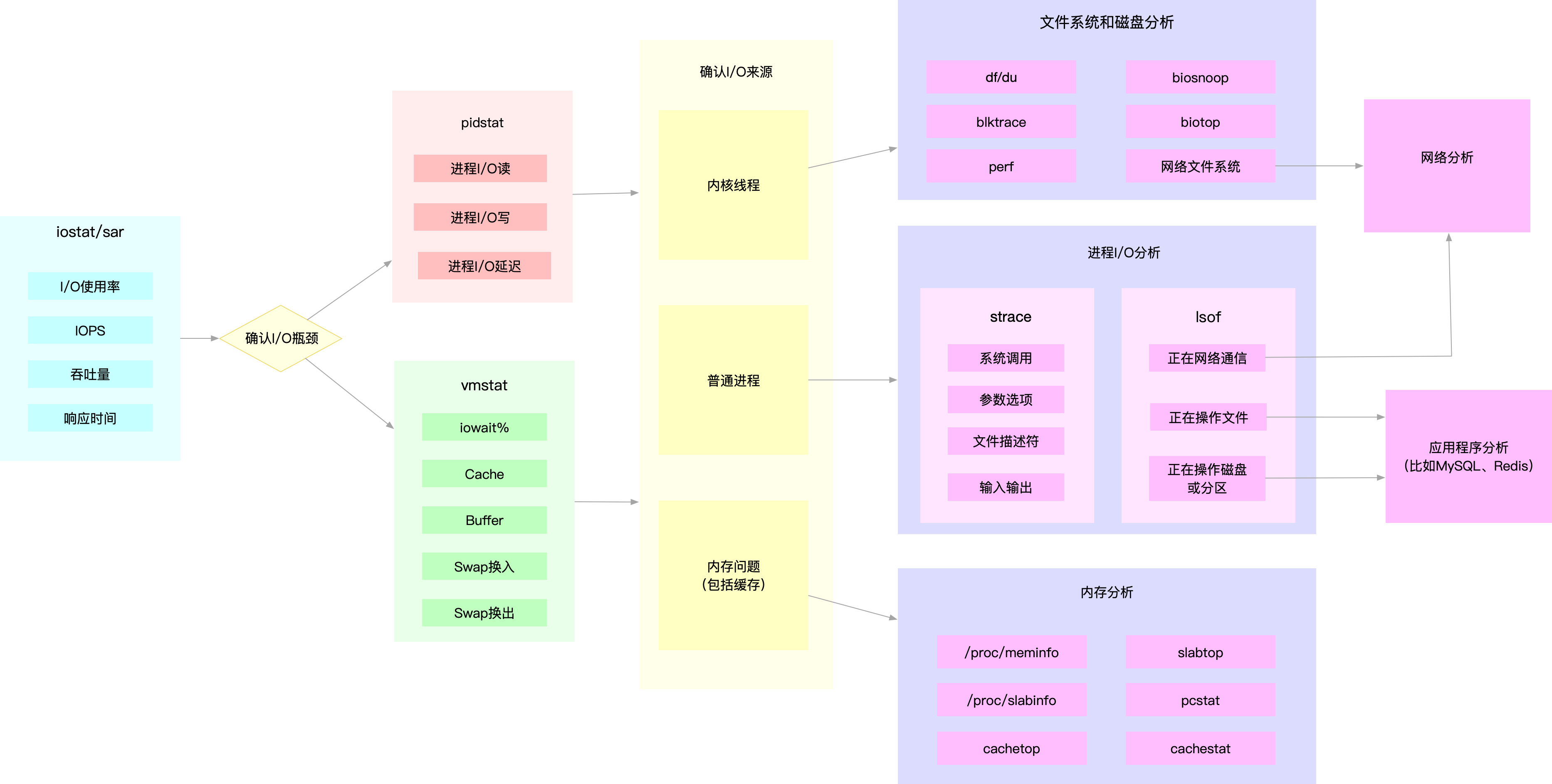
30. IO总结
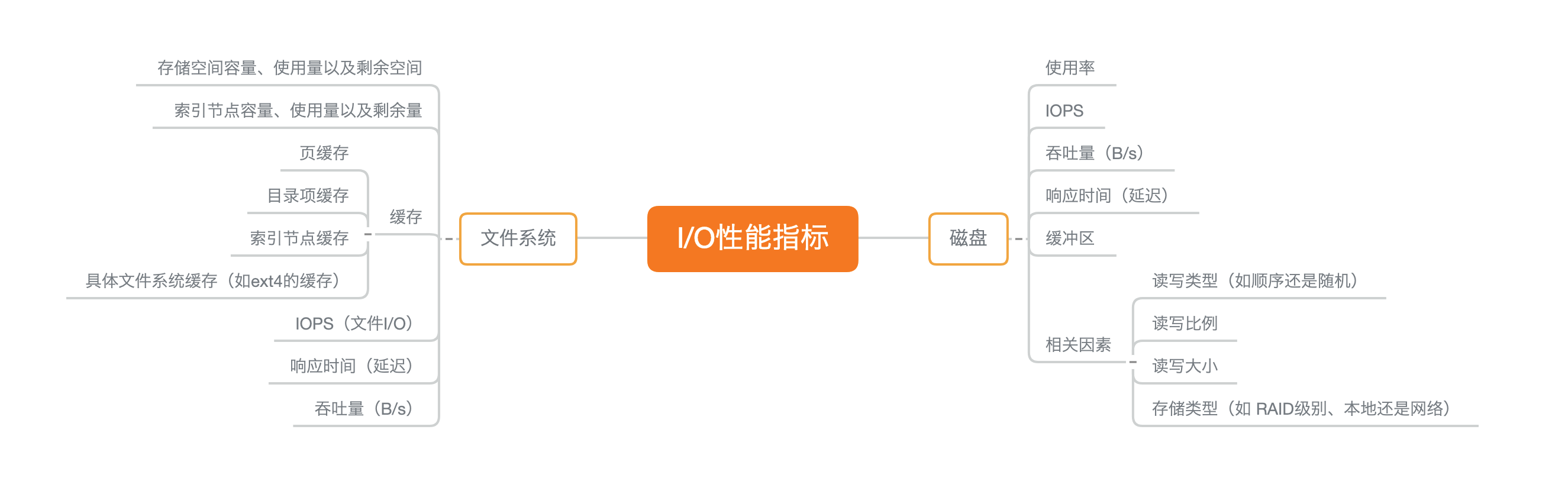
- IO排查思路
- 用iostat发现性能瓶颈
- pidstat定位进程
- 分析IO行为等
31. IO优化思路
- fio测性能,主要关注: slat(submit), clat(complete), lat, bw(吞吐量), iops
- 应用程序优化
- 追加写代替随机写,减少寻址开销
- 借助系统缓存
- 构建自己的缓存或借助redis等外部缓存
- 其他用xx函数代替xx函数(fopen, fread, mmap, fsync)
- 共享磁盘时使用cgroups的IO子系统限制单个进程的IO
- 文件系统优化
- 选用合适的文件系统: 比如ext(可收缩), xfs(支持大于16TB)
- 配置如日志模式,挂在选项
- 缓存如脏页的频率限额
- 磁盘优化
- SSD
- RAID
- IO调度算法
- 对应用程序进行磁盘级别隔离
- 增加预读大小
网络
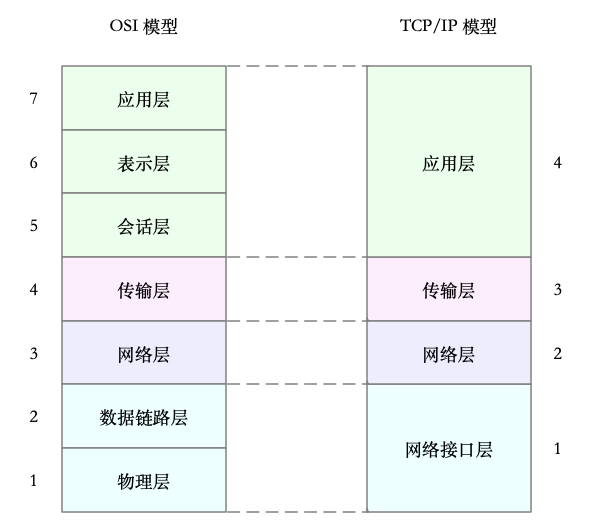
33. 概述
- OSI, TCPIP模型
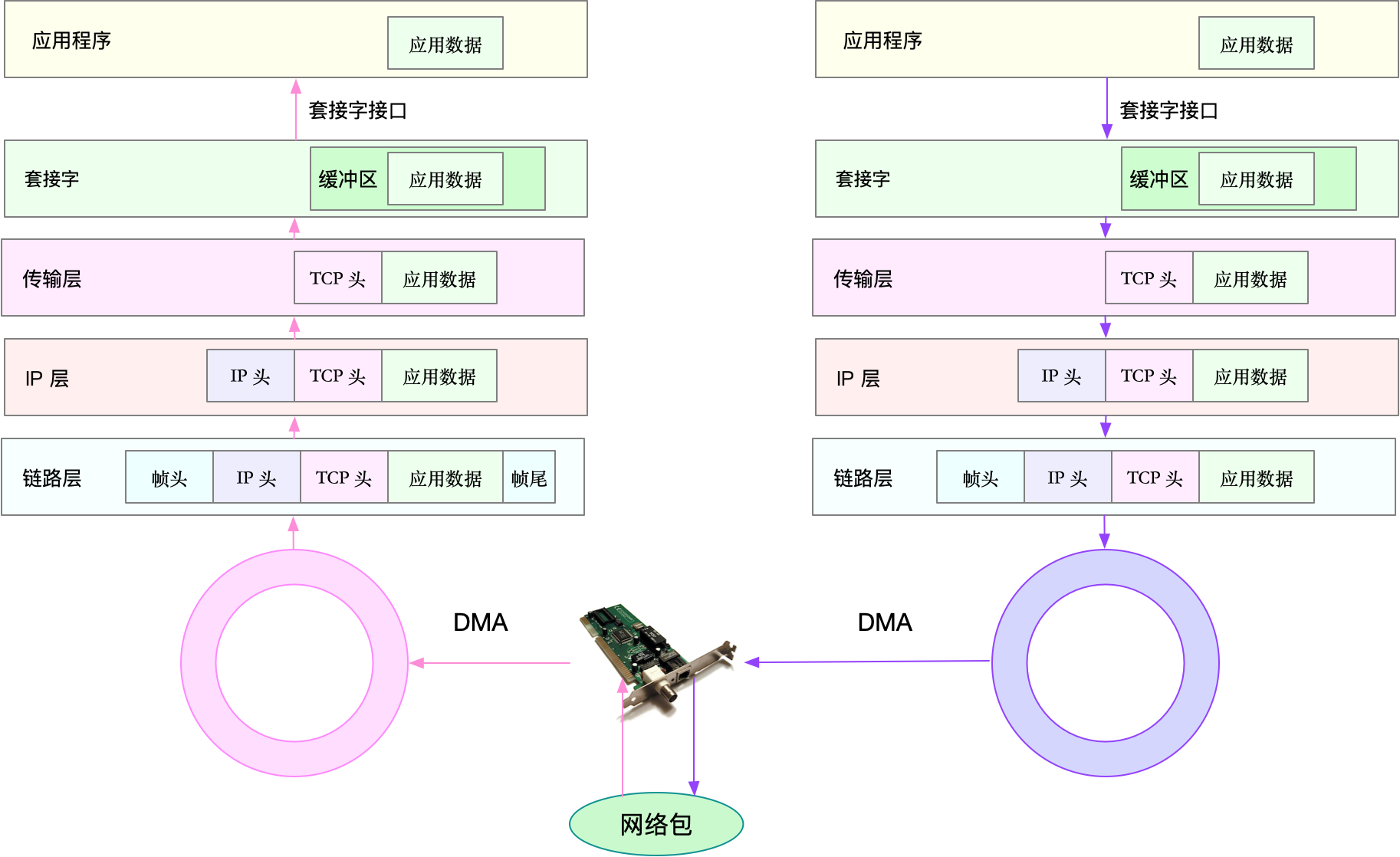
- 网络包流程
指标
- 性能
- 带宽 b/s
- 吞吐量 b/s
- 使用率: 吞吐量/带宽
- 延时(区分不同场景)
- PPS(包/秒), 评估转发能力
- 其他: 可用性,并发连接数,丢包率,重传率
- 网络配置命令: ifconfig, ip -s addr
- 状态: RUNNING(ifconfig), LOWER_UP(ip)
- MTU: 最大传输单元,最大IP包大小,超过则分片
- IP, MAC, 子网
- TX, RX的error
- 套接字状态
- netstat -nlp, ss -nlp
- l: 只监听套接字,n:显示数字地址和端口 ,p:进程信息
- 套接字处于establish
- recv-q: 套接字缓冲未被应用程序取走的字节数
- send-q: 未被远程主机确认的字节数
- 处于listening
- recv-q: sync backlog(半连接队列长度,即三次握手未完成)当前值
- send-q:sync backlog最大值
- 套接字处于establish
- 协议栈统计
- sar -n DEV(网络接口) 1
- rxpck/s 接收pps
- rxkB/s 接受吞吐量
- rxcmp/s 接受压缩包数
- %ifutil 网络接口使用率
-
网卡速度: ethtool eth0 grep Speed - 延时: ping, icmp协议
- sar -n DEV(网络接口) 1
35. 单机并发(C10K, C1000K)
C10K
- C10K(并发1w)的物理资源: 2GB, 千兆网卡
- 每个请求内存200KB, 网络带宽100KB (OK)
- IO模型优化: IO多路复用
- 水平触发
- 只要文件描述符可以非阻塞执行IO,即触发通知
- select, poll 对文件描述符进行轮询
- 一个线程监控一批套接字
- 边缘触发
- 只有文件描述符发生改变时,触发通知,尽可能多的执行IO
- epoll(目前主流), 优势在于:红黑树,只关注有IO事件发生的文件描述符而非轮询
- 异步IO
- 水平触发
- 工作模型优化
- 主进程(bind+listen)➕多个worker子进程(accept or epoll_wait)
- 监听相同端口的多进程
C1000K
- 一些方案: 多个队列网卡, 中断负载均衡,CPU绑定,RPS/RFS,网络包处理卸载,网络设备
C10M
- 软硬件优化到头了,原因是linux内核栈工作太多
- 方案:跳过内核协议栈,直接把网络包发送至应用程序
- DPDK: 由用户态进程通过轮询,处理网络接收
- XDP(eXpress Data Path): 允许网络进入内核协议栈之前进行处理,和之前的bcc-tools一样基于eBPF
36. 各协议层性能
- 网络层,网络接口层: PPS
- TCP/UDP: iperf3
- 服务端: iperf3 -s -i 1 -p 10000
- 应用端: iperf3 -c [host] -b 1G -t 15 -P 2 -p 10000
- 应用层HTTP: wrk, Jmeter, locust等工具
37. DNS解析
- nslookup time.geekbang.org
- dig +trace(开启追踪) +nodnssec(禁止DNS安全扩展) time.geekbang.org
- dnsmasq开启dns缓存
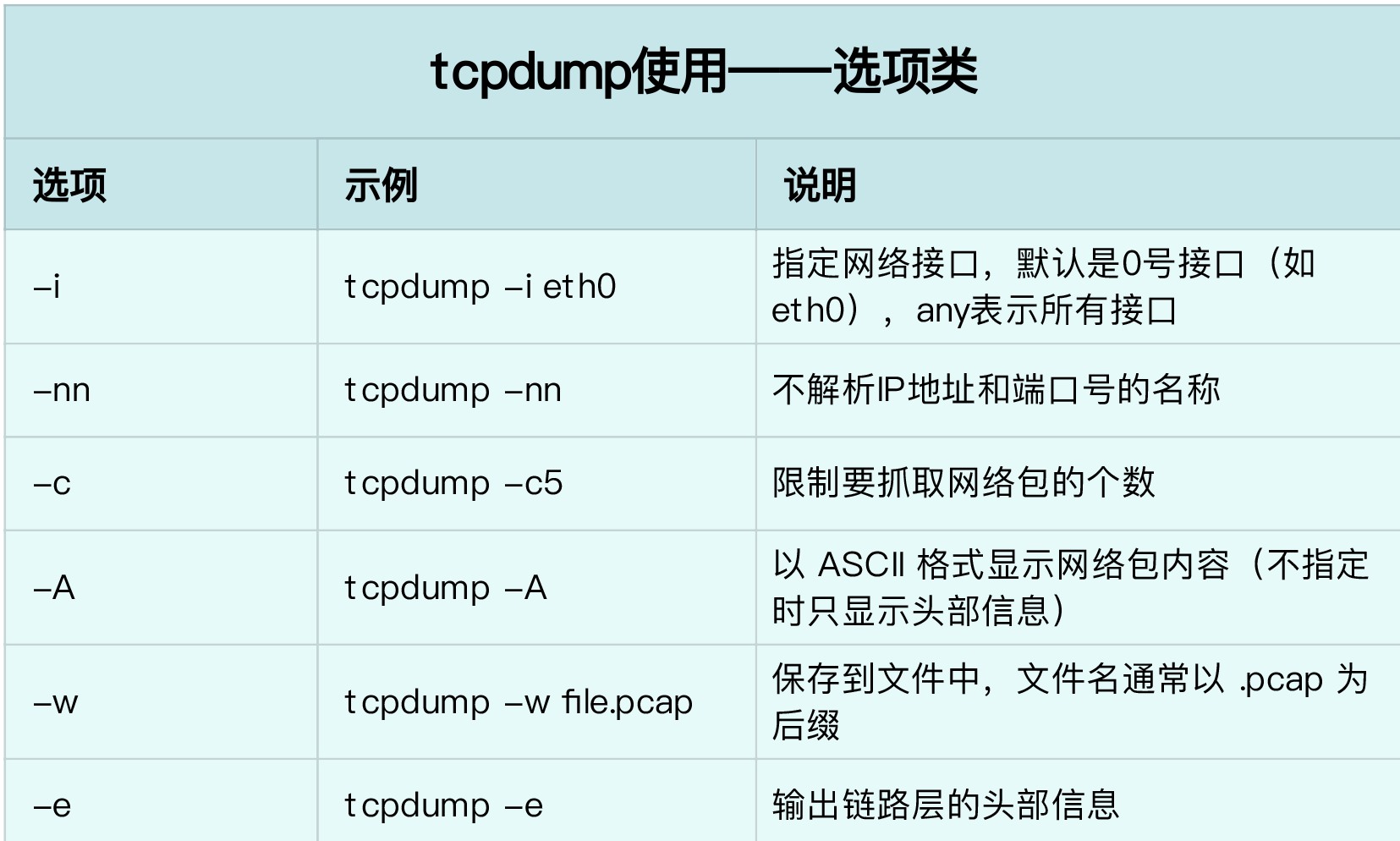
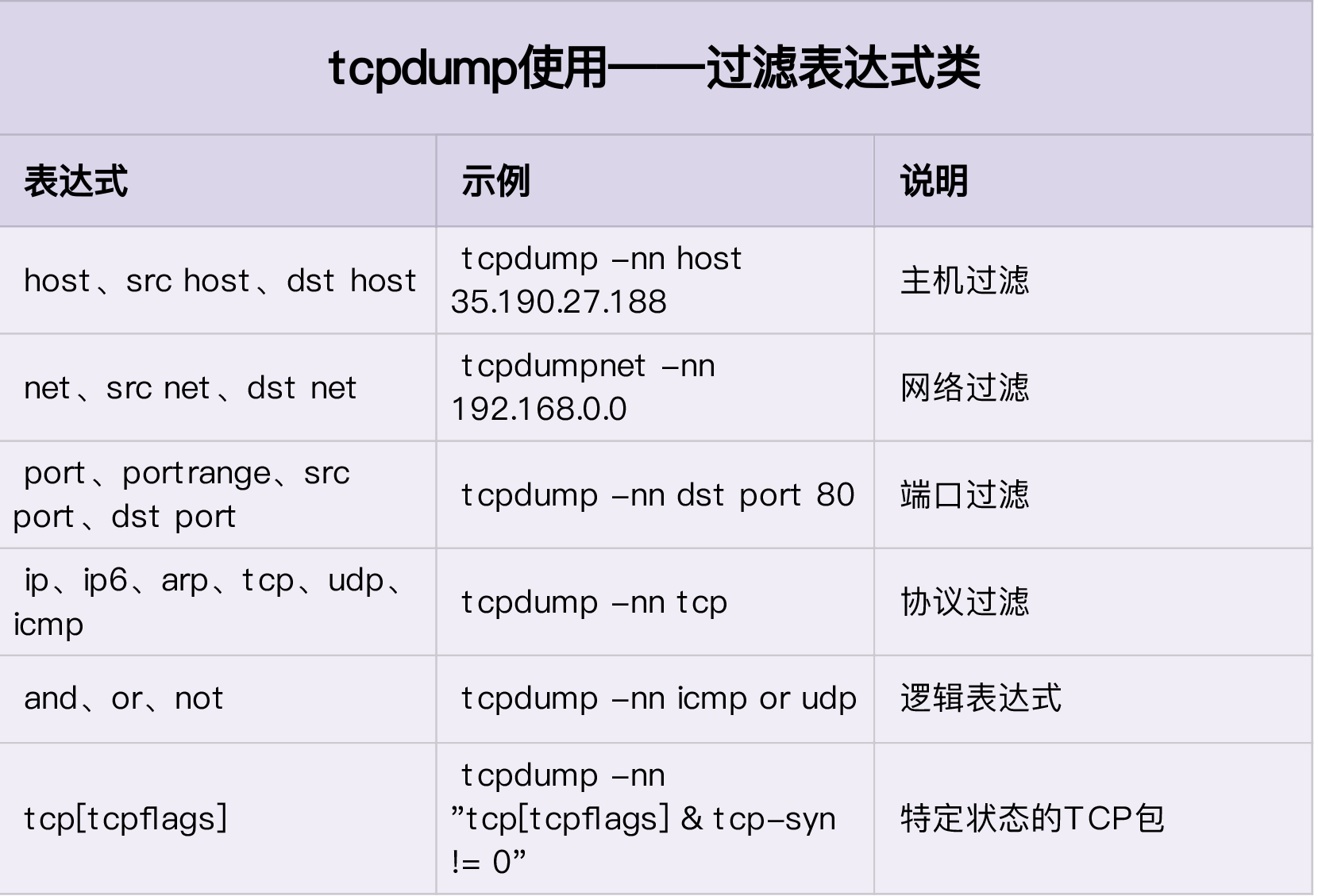
38. tcpdump, wireshark
- tcpdump使用
其他
32. 书单推荐
- 鸟哥的linux私房菜
- 深入理解计算机系统 官网
- Linux程序设计 , UNIX环境高级编程
- 深入Linux内核架构
- 性能之巅
