最后修改时间: 2019-03-25
1. 架构的定义
- 一些相近的词: 系统与子系统,模块(逻辑角度)与组件(物理角度),框架与架构
- 作者定义架构:系统的顶层结构;详细来说需要明确系统包含哪些个体,并且明确这些个体的运作规则
- 神评论:
搬砖的:“头,我们要造什么?”;(做什么系统?)
工程师:“龙之梦商城”;(XXX系统,比如微博系统)
搬砖的:“图纸画出来了嘛?”;(架构是怎么设计的?)
工程师:“一楼主要以女性消费为主体、二楼以大众娱乐为主体、三楼以美食为主体”;(相当于微博系统中的各个子系统,比如评论子系统、动态子系统、消息子系统)
搬砖的:“头,说人话”;
工程师:“一楼有卖衣服、化妆品的,二楼有唱歌、看电影的,三楼有吃的”;(【模块】按照逻辑区分,比如存储数据模块、搜索模块、消息推送模块)
搬砖的:“有没有很知名的店啊?”;
工程师:“有的,一楼有香奈儿、优衣库...、二楼有好乐迪、万达影院....、三楼有海底捞、避风塘.....”;(【组件】按照物理区分,存储数据模块对应Mysql、搜索模块对应ElasticSearch、 消息推送模块对应Kafka)
搬砖的:“对了,头,商城大门有啥需要叮嘱的施工规范不?或有啥简化施工工艺的新技术嘛?”;(有框架的可以用吗?)
工程师猛吸了一口烟,把烟头扔在地上,用皮鞋左右撵了两下,缓缓从嘴里崩出四个字。 “老样子吧”。(Spring全家桶甩起来)
2. 架构设计的历史背景
- 机器语言(01操作)
- 汇编语言(面向机器,且不同CPU的命令不同)
- 高级语言
- 第一次软件危机: 产生了结构化程序设计方法
- 第二次软件危机:面向对象
- 软件架构:组件化模块化
3. 架构的目的
解决软件系统复杂度带来的问题
4. 复杂度来源: 高性能
- 单机: 多线程/进程,多进程通信,多线程并发
- 集群:复杂度包括任务分配,任务分解
5. 复杂度来源: 高可用
- 本质在于冗余
- 3中高可用
- 计算高可用
- 存储高可用
- 高可用状态决策
- 独裁(独裁者出现问题怎么办)
- 协商(通信出现问题怎么办)
- 民主(复杂度高)
6. 复杂度来源: 可扩展
- 本质在于封装
- 复杂度在于:
- 如何拆分变化层和稳定层
- 如何设计两层的接口
7. 复杂度来源: 低成本、安全、规模
8. 架构设计三原则
- 合适(人、技术积累、业务场景)
- 简单
- 演化(不需要一步到位)
9. 架构设计案例
淘宝“买一个”=》“oracle“=〉“java1.0 2.0 3.0”=》“分布式”的例子
10. 复杂度识别(设计微博的例子)
- 需求: 设计一个消息队列系统,传递系统间消息
- 背景
- 中间件团队6人
- 主要用java
- linux,mysql
- 单机房
- 假设:每天生成1000w微博,
- 评估
- 高性能:十个子系统1亿次读取请求,平均每秒115次写消息,1150次读,峰值x3,即TPS:345,QPS:3450,按未来发展x4, QPS: 13800, 对性能要求还是比较高的
- 高可用:比如对审核系统,如果没有审核导致处罚法律很严重等,所以对消息写入、存储、读取都需要高可用
- 可扩展性:不需要
11. 设计备选方案
- 不需要太详细
- 3-5个为佳
- 差异要明显
- 不要仅限于自己熟悉的
12. 评估选择备选方案
- 错误思路: 最简派,最熟派,最牛派,领导派
- 360度测评
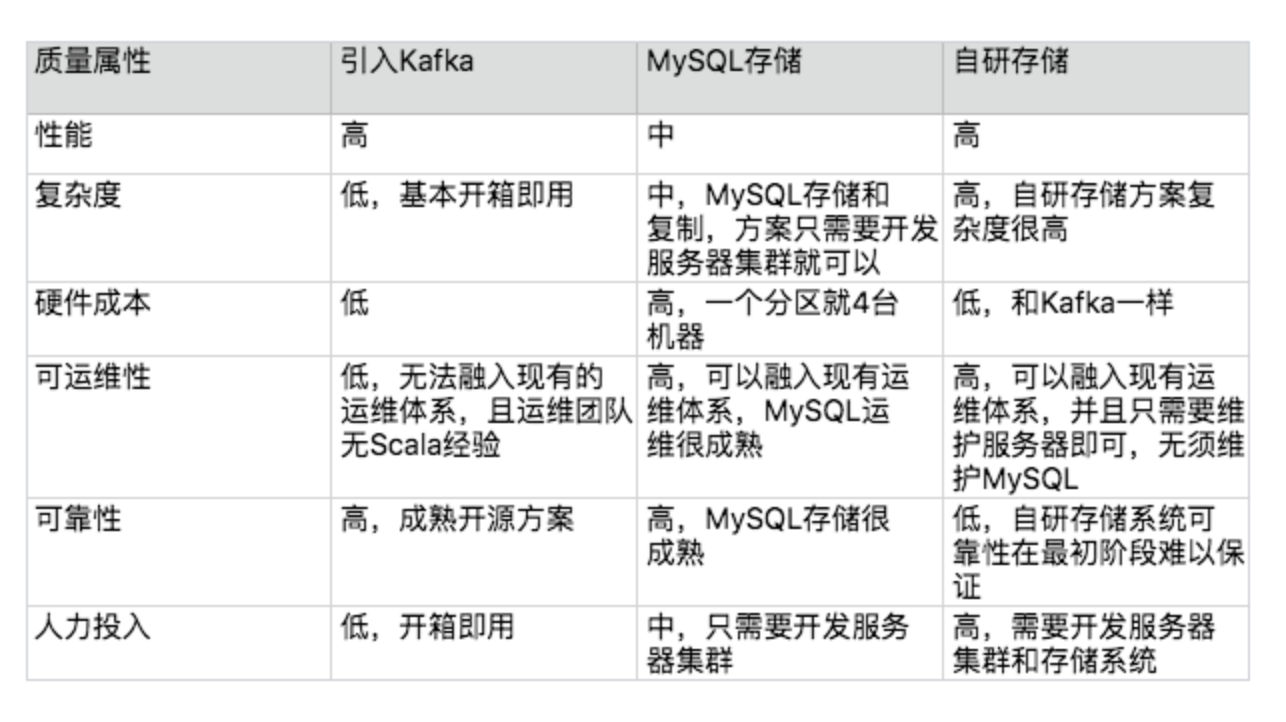
13. 详细方案设计(如果选了上面的mysql方案)
- 数据库表如何设计
- 数据如何复制
- 主备如何转换
- 业务如何读取
- 业务如何写
- 业务和队列的通信协议
14. 高性能数据库集群:读写分离
- 复制延迟
- 写操作后的读操作发给主机
- 读从机失败再读主机
- 核心业务不分离
- 分配机制
- 代码封装
- 中间件
15. 高性能数据库集群:分库分表
- 业务分库,以下是带来的问题
- join
- 事务
- 成本
- 分表
- 垂直切:不常用但占空间的列拆分出去
- 水平切(当行数达到千万时需要开始关注分表)
- 路由问题:范围路由、hash路由、配置路由
- join,count,order操作都有影响
- 当数据库压力大时的操作顺序
- 硬件优化: 固态、内存
- 数据库调优: 加索引、慢查询优化
- 引入缓存
- 读写分离
- 分库分表
16. 高性能nosql
not only sql, 都是为了解决关系数据库的某个问题
- kv数据库: redis,解决无法存储数据结构问题
- 文档数据库: mongo, 解决强schema问题
- 列式数据库:HBase,解决大数据场景的IO问题
- 全文索引数据库:ES, 解决全文搜索问题(只能like)
17. 高性能缓存架构
缓存的使用场景
- 复杂运算比如count(*),mysql每次都要计算的话很慢
- 读多写少,我的理解是缓存主要是解决读的问题,比如首次访问从RDBMS写入数据到缓存,接下来的访问都走缓存
缓存穿透: 即没生效,穿透了缓存去查询数据库
- 被访问数据不存在,解决方法是如果确实不存在,直接设置一个默认值作为key,下次访问缓存的时候就知道了
- 生成缓存数据慢或消耗资源。比如爬虫会遍历不同的数据,没好办法,问题也不严重,还是从反爬虫入手。
缓存雪崩: 缓存过期重新生成的时间内收到大量请求
- 更新锁: 只有一个线程可以更新缓存,其他的要不等待,要不返回默认值
- 后台更新: 由后台定时更新,而不是由业务线程更新
- 双key策略: key有失效时间,key1无,如果读取不到key就读取key1,并触发事件同时更新两个key
缓存热点: 对短时间内超高访问数据的解决方案
- 复制多份副本,放到不同服务器
- 注意不要设置同一个失效时间以免雪崩
mysql的缓存
- 查询语句缓存: 如果查询缓存打开,mysql会优先查询是否命中查询缓存中的数据。但是条件苛刻不可控。
- innodb buffer pool(没搞懂): 缓存的是磁盘上的分页数据,sql的执行还是省不了。
18. 单服务器高性能模式PPC与TPC
高性能的要点
- 高性能架构设计:决定上限
- 提高单服务器的性能
- 如何管理请求
- 如何处理请求
- 如果单服务器无法支撑,设计服务器集群
- 提高单服务器的性能
- 具体代码实现: 决定下限
PPC和TPC
- PPC, process per connection,每次有新连接就新建一个进程,缺点是fork进程代价高
- TPC, tread per connection, 每次有新连接就新建一个线程,创建线程代价低,但多线程可能会互相影响,导致死锁或单一线程崩溃导致进程崩溃
- PPC有prefork, TPC有prethread,都是提前创建来解决新建消耗资源的问题。
- PPC和TPC都是传统的单服务器高性能模式,最大连接数都是几百个,适用于常量而非海量连接数的场景
书
UNIX网络编程 三卷本
io之同步,异步,阻塞(bio),非阻塞(nio) (需要注意不同语境)
- 同步异步: 关注的是消息通讯机制(synchronous/asynchronous communication),即被调用者(系统、执行者)是否会通知/回调
- 同步指的是收到IO请求后,系统不会立刻响应, 等到处理完成才会通过系统调用的方式通知
- 异步指的是系统先告诉应用程序请求已收到,等处理完成后再通过事件通知的方式告知结果
- 阻塞与非阻塞: 关注的是程序在等待调用结果(消息,返回值)时的状态,即调用者(应用程序)在发起调用后是否还会干别的事
- 阻塞调用是指调用结果返回之前,当前线程会被阻塞, 不能执行其他任务。PPC和TPC都属于这个.
- 非阻塞调用指,该调用不会阻塞当前线程。
19. 单服务器高性能模式:Reactor与Proactor(未完成)
这一节没看懂,这俩应该属于io多路复用(io multiplexing),而非作者说的nio
io多路复用应该和上面写的同步,异步,阻塞(bio),非阻塞(nio)是平行关系,但不确定
https://blog.csdn.net/mx472756841/article/details/70145762
https://segmentfault.com/a/1190000003063859
https://time.geekbang.org/column/article/8805
Reactor
Reactor 模式的核心组成部分包括 Reactor 和处理资源池(进程池或线程池)
比方
Reactor与Proactor能不能这样打个比方:
1、假如我们去饭店点餐,饭店人很多,如果我们付了钱后站在收银台等着饭端上来我们才离开,这就成了同步阻塞了。
2、如果我们付了钱后给你一个号就可以离开,饭好了老板会叫号,你过来取。这就是Reactor模型。
3、如果我们付了钱后给我一个号就可以坐到坐位上该干啥干啥,饭好了老板会把饭端上来送给你。这就是Proactor模型了。
#20. 高性能集群负载均衡:分类及架构
复杂性
- 增加一个任务分配器,也叫负载均衡器
- 选择任务分配的算法
负载均衡分类
下面的123层可以依次一起用,组成了最强负载均衡,实际情况按日活到QPS,TPS来估算再进行设计
- 第一层: DNS负载均衡,地理级别的均衡
- 缺点:
- 更新不及时,DNS缓存时间长
- 扩展性差,域名商控制
- 不可能所有机器都配置公网ip
- 优点
- 简单便宜
- 就近访问提升速度
- HTTP-DNS: 使用http协议实现私有的DNS
- 缺点:
- 第二层: 硬件负载均衡,比如F5,A10
- 缺点:
- 贵
- 扩展性差
- 优点:
- 功能强大,高性能(百万级),高稳定,支持防火墙,防DDOS攻击
- 缺点:
- 第三层: 软件负载均衡,比如nginx(软件的7层负载均衡,万级), LVS(linux内核的4层负载均衡,十万级)
- 优缺点和硬件相反即是
- 4层和7层区别在于协议和灵活性,7层支持http,email;4层几乎所有应用都能做
- ps: 评论中有人提到nginx的新特性也能支持4层负载均衡
估算例子
1000wDAU => 平均每秒116 => QPS x10 => 高峰 x10 => 图片等静态资源x10(这一步可能夸张了?)
=> 异地多活x2 => 半年增长x2 。即QPS=464000
#21. 高性能负载均衡算法
轮询/加权轮询
- 优缺点都是简单,是最常用的算法,但无法感知服务器状态差异
负载最低优先(从服务端的角度)
- LVS可根据连接数来判断服务器状态
- nginx可根据http请求数(需扩展)
- 自己开发可以看业务特点是IO密集还是CPU密集或其他。
性能最优:优先分配给响应时间低的(从客户款的角度)
hash算法
根据ip地址或者sessionid或其他,确保同一个ip/session在同一个服务器上处理
#22. CAP理论
Robert Greiner的blog
在一个分布式系统(指互相连接并共享数据的节点集合)中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Available)、分区容错性(Partition Tolerence)三者中的两个,另外一个必须被牺牲.
- 第二版强调了:
- 互相连接并共享数据: Memcache集群不是,而Mysql集群进行数据的复制,所以mysql集群是cap的讨论对象
- 读写: 比如zookeeper的选举就不是讨论对象
- cap定义: (这个第二版的解释有点晦涩)
- 一致性: 对某个指定客户端来说,读操作保证返回最新的写操作数据
- 可用性:非故障节点在合理时间返回合理响应(非错误或超时)
- 分区容错性: 当出现网络分区后,系统能够继续“履行职责”。
- cap应用(分布式环境,分区是必然现象,必须满足p)
- 也就是说在不同节点数据不一致的时候,要么等同步完成(CP),要么返回旧的数据(AP)
- 其他:
- Paxos属于CP,具体不懂,以后再补充
23. CAP, ACID, BASE
- CAP的关键细节:
- cap关注的是数据而非系统。根据不同的数据要求,可以在cp和ap之间切换
- CAP理论是忽略延时的(心跳也有延时),而实际应用中延时是无法避免,完美CP不存在(所以比如用户余额和商品库存有时必须选择CA,不能多点写入)
- 正常情况下,p分区不出现,同时满足AP
- AP方案中牺牲一致性只是指分区期间,而不是永远放弃一致性。
- ACID
- CAP是分布式系统设计理论, ACID是数据库事务完整性理论
- BASE: 是CAP理论(上面的第2,4点的延伸)
- (Basically available)基本可用
- (Soft state)软状态
- Eventual Consistency(最终一致性)
24. FMEA:一种可用性分析方法
Failure mode and effects analysis(故障模式与影响分析),其实就是多设计一些异常case,看系统是否依然稳定
原来:
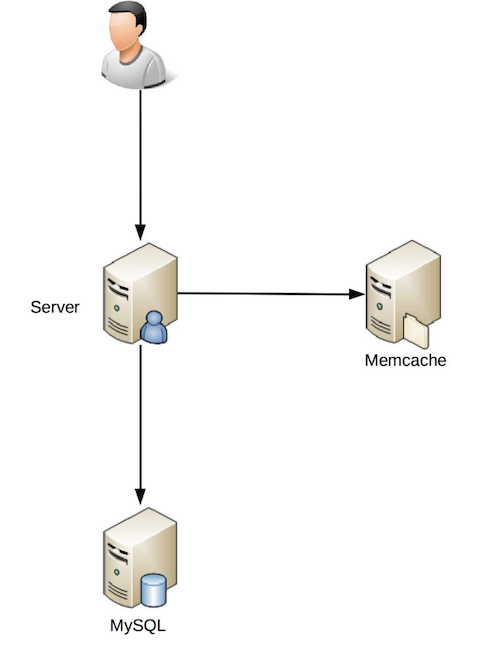
FMEA分析
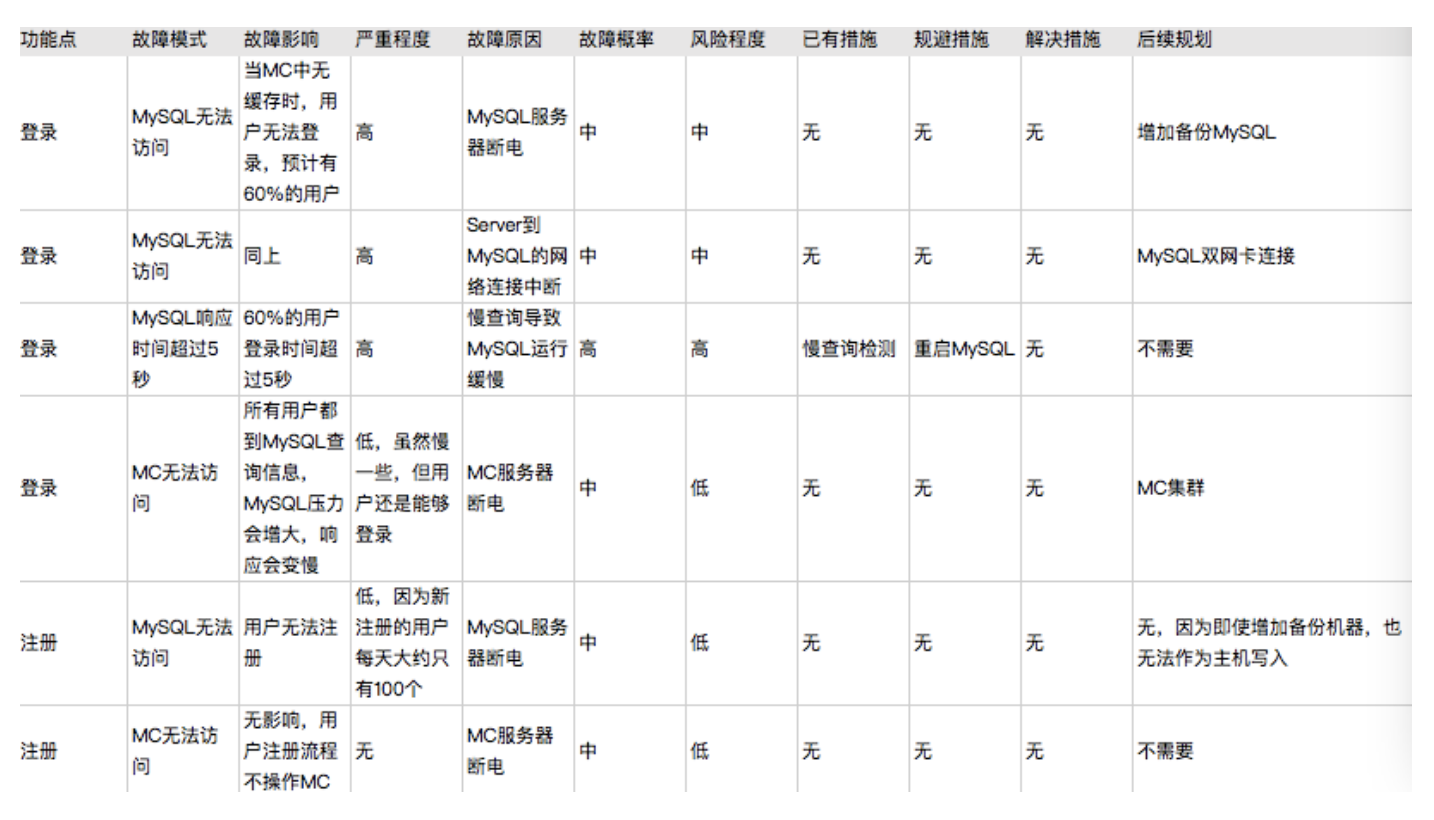
改进后
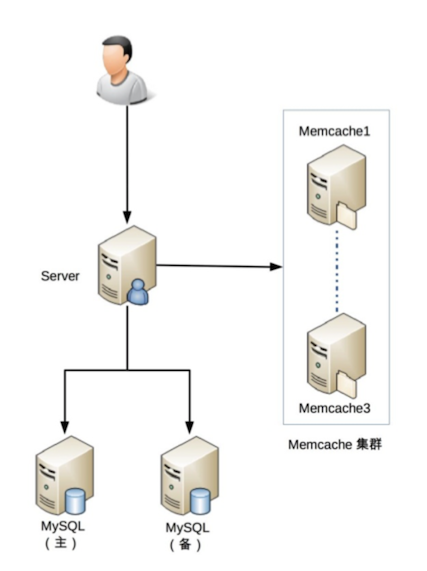
25. 高可用存储架构:双机架构
复杂性在于: 如何应对复制延迟和中断导致的数据不一致
- 主备复制: 备机起备份作用,不承担业务读写操作。适用于内部系统
- 主从复制: 从机起负责读业务,可分散压力,但客户端需要感知主从关系
- 双机切换(包括主从/主备):
- 解决上面两条的两个问题
- 主机挂无法写问题
- 如果主机无法恢复,需要人工指定新主机问题
- 设计复杂,需要考虑以下点:
- 主备状态判断: 状态传递的渠道可以是[互连,中介,模拟],状态内容例如[机器掉电,进程存在,响应缓慢]
- 切换决策:主机恢复之后怎么办,半自动还是全自动
- 数据冲突怎么办
- 解决上面两条的两个问题
- 主主复制: 都负责读写,互相复制数据。对数据设计有要求,适用于可丢失可覆盖的数据。
26. 高可用存储架构:数据集群和数据分区
数据集群: 主要考虑硬件故障
- 数据集中集群(比如zookeeper): 类似于上一章的主备主从,区别是至少3台
- 写操作都由主机完成,适合数据量不大的场景
- 复杂度提升,体现在数据复制,监测主机状态,新主机决策
- 数据分散集群(比如hadoop)
- 需要考虑均衡性,容错性,可伸缩性
数据分区: 主要考虑极端灾害和事故
- 需要考虑均衡性,容错性,可伸缩性
- 需要考虑: 数据量,地理分区规则,复制规则
- 三种复制规则:
- 集中式:北上广三机房同时把数据复制到西安机房。特点是简单
- 互备式: 北上广三机房互相备份。特点是复杂(尤其是加了新的地区怎么办),但直接利用已有机房省钱
- 独立式:例如上海->杭州,北京->天津,每个机房有自己的备份中心。特点是简单稳定,但成本很高
27. 计算高可用架构
关键点在于以下两点,复杂度比存储高可用低(不需要考虑CAP)
- 哪些服务器可执行任务
- 任务失败如何重新执行
- 主备主从,文章中说这里的主备主从和存储那章的类似,但是需要手动切换,又说下面的集群是包含2台机器的,所以这里的主备主从和集群的区别难道只是手动切换?
- 集群
- 对称集群:除了任务分配,所有机器身份相同
- 非对称集群: 除了任务分配,不对称比如master,slave。任务分配和角色分配都要比对称集群更复杂
28-30. 业务高可用: 异地多活
28. 分类
- 同城异区
- 目的:解决火灾断电等单机房可能出现的事故
- 特点:单城市几乎不需要延迟
- 跨城异地(难度最高)
- 目的:解决超级大水灾这种单城市无法解决的灾难
- 特点:只能用于对数据一致性要求不高的业务(涉及钱的不要跨城异地了)
- 跨国
- 目的:为不同国家提供业务,或者不需要实时的业务场景
29. 跨城异地四大原则
- 核心业务异地多活
- 保证核心数据的最终一致性
- 采用多种不同的同步方式
- 消息队列
- 二次读取
- 存储系统自带的同步
- 回源读取,路由判断该去哪里读数据
- 重新生成数据
- 保证绝大部分用户而非100%
30. 异地多活设计四大步骤
- 业务分级
- 访问量
- 核心程度
- 收入程度
- 数据分类
- 数据量
- 唯一性,比如用户id必须唯一
- 实时性
- 可丢失性
- 可恢复性
- 数据同步
- 见上一章
- 异常处理
- 双通道分别通过内外网同步
- 同步和访问结合(没看懂)
- 日志记录
- 用户补偿
31. 应对接口级故障
网络和硬件没问题,业务出问题比如压力太大,处理原则是保证核心业务和核心用户
- 降级: 保证核心业务
- 熔断: 和降级不同的是,当外部接口过慢导致自身过慢的话,访问外部接口立刻访问错误
- 限流
- 基于请求限流(外部),比如1分钟处理1w个用户
- 基于资源限流(内部),比如连接数,线程数,CPU使用率
- 排队:比如堆在kafka里面,但是等太久体验未必比限流好
32. 可扩展架构基本思想和模式
- 基本思想是拆分,有三种拆分思路,从大到小排列(这里不清楚为啥服务和功能要分开,感觉很像,后面再看下)
- 面向流程: 典型的比如分层架构,例子:展示层,业务层,数据层,存储层
- 面向服务:比如SOA,微服务,例子:注册,登陆,安全设置
- 面向功能:比如微内核架构,例子:注册包括手机注册、邮箱注册
33. 传统的可扩展架构模式
- 分层架构: C/S, B/S, MVC, MVP
- SOA: 用ESB(Enterprise Service Bus)整合兼容各个独立系统,和微服务的拆分系统想法相反,一般互联网公司不会用
34. 理解微服务架构
看了评论之后的感觉就是慎用微服务,要团队和架构都够强才可以
- 对比SOA
- 服务粒度: 细
- 服务通信: Smart endpoints and dumb pipes,指的是仅仅做消息传递而对内容一无所知
- 服务交付: 快速交付,依靠于各种自动化测试、部署等
- 坑
- 服务划分过细导致的
- 系统间的复杂度增加
- 维护成本增加
- 调用链太长导致的
- 性能下降
- bug定位困难
- 没有自动化支撑导致的低效,比如10个服务x10台机器的部署
- 服务治理导致的各种混乱比如,比如对于故障机器、新增机器的感知
- 服务划分过细导致的
35-36. 微服务最佳实践
方法篇
- 服务粒度: 按开发阶段平均3个人一个微服务, 决定微服务的数量
- 拆分方法:
- 基于业务: 容易扯皮
- 基于可扩展: 稳定服务,变动服务
- 基于可靠性: 核心服务、非核心服务
- 基于性能
- 基础设施: (按重要性先后)
- 服务发现,服务路由,服务容错
- 接口框架,API网关
- 自动化部署,自动化测试,配置中心
- 服务监控,服务跟踪,服务安全
实践篇
太细了,暂时没必要记录
37. 微内核,插件化架构
- 基本架构包括两类组件: 核心系统和插件模块
- 设计关键点: 插件管理(加载、注册等),插件链接(OSGI, 消息模式、依赖注入等),插件通信(必须经过核心系统)
- 案例1: OSGI架构
- 案例2: 规则引擎架构,
- 和策略模式很像,额外的好处在于不用改代码,且可以用业务人员易于理解操作的方式操作
- Drools
- Esper
38. 如何判断技术演进方向
- 三种人
- 潮流派:哪个火用哪个,问题在于新技术的坑和发现不适用后的人力放飞
- 保守派:如果有一把锤子,所有问题都变成了钉子,嗯说的就是我
- 跟风派:其他公司用的啥
- 两类业务
- 产品类: iPhone,杀毒软件,浏览器等。特点是用户对产品是独占的,这类产品技术创新推动业务发展
- 服务类:微信,淘宝等。特点是服务用户越多,服务价值越大,这类产品业务推动技术发展,互联网大多属于此类
- 公司在不同时期的复杂度不一样,架构师应该基于业务发展进行判断
39. 互联网技术演进模式
不同时期的差别主要体现在:
- 复杂度
- 初创期:需要快速迭代,但人却是最少,应该能买就买,能开源就开源
- 发展期1之堆功能
- 发展期2之优化: 优化派和架构派
- 竞争期: 系统越来越多越来越乱,此时应该平台化(不重复造轮子),服务化(系统交互)
- 成熟期
- 用户规模
40-43 架构模版
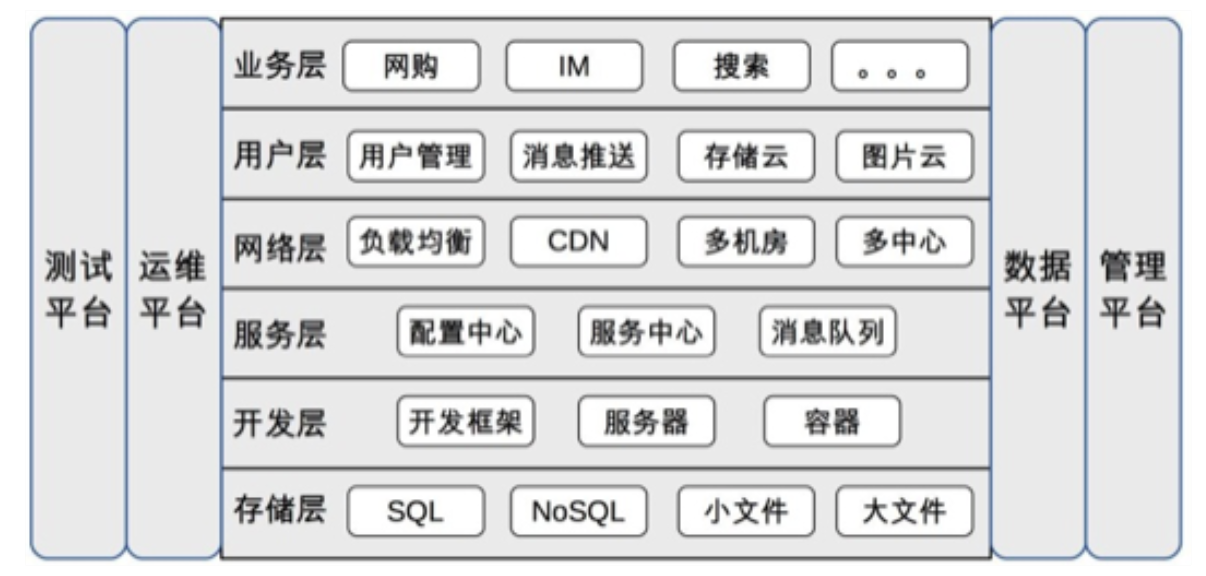
很多以前有过,以下只记录一部分
- 服务层: 当系统间依赖度越来越高
- 配置中心
- 服务中心
- 服务名字系统(Service Name System),和DNS类似,告诉你去哪里
- 服务总线系统: 帮你做请求
- 消息队列, 特点是异步
- 网络层
- 负载均衡
- CDN(云服务商)
- 多机房
- 多中心(要求每个中心都要对外提供服务)
- 用户层
- 用户管理
- SSO单点登录,例如cookies,token,当前火热的方案是CAS
- 授权登陆,OAuth
- 推送,优先第三方
- 存储云图片云(CDN+小文件存储)
44. 架构模版之平台技术
- 用户管理
运维平台
- 职责
- 配置
- 上线
- 监控
- 应急
- 设计
- 标准化
- 平台化
- 自动化
- 可视化
测试平台
- 职责
- 单元测试
- 集成测试
- 接口测试
- 性能测试
- 设计
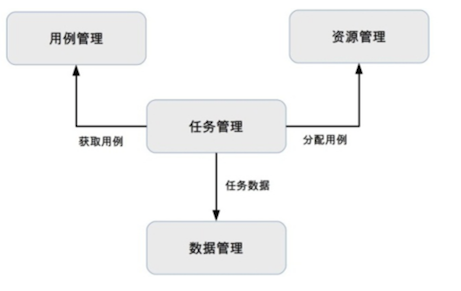
- 用例: 例如单元测试用例是代码、接口测试用例可以用 Python,可靠性用shell等
- 资源: 例如硬件
- 任务
- 数据:执行结果,时间,效率,CPU的记录分析
数据平台
- 数据应用:推荐、广告、防刷
- 数据分析:统计分析、挖掘、深度学习
- 数据管理:采集存储、安全、访问
管理平台
- 身份认证
- 权限
评论: jira+gitlab+jenkins+nexus+bearychat 最简单的DevOps平台
45-47. 架构重构
- 按照架构三原则的演化原则。少部分演化是重写,大部分是重构。重构的难点在于:
- 业务上线,不能停
- 关联方太多,牵一发动全身
- 旧架构约束
- 三原则:
- 有的放矢,避免“新官上任三把火”
- 合纵连横(沟通)
- 运筹帷幄(优先级,分类,*先易后难)
- 先易后难的原因
- 复杂的问题有时必须解决其他容易的问题
- 当简单问题解决后,复杂问题可能不再复杂或消失
- 提升士气
- 一开始的分析不一定全面,随着项目进行会逐渐浮现
49. app架构的演进
- webapp: 在web外面包个app的壳,成本低,遵循合适、简单原则
- 原生app: 随着移动设备、移动互联网的兴起,演化原则
- Hybrid app: 对体验要求不高的采用web方式,合适原则
- 容器化和组件化
- 跨平台app,例如react naive
50. 架构设计文档模版
备选方案模版
- 需求介绍(背景,目标,范围)
- 需求分析(全方位描述需求相关的信息,包括)
- 5w: who, when ,what, why, where
- 1H: how(关键业务流程)
- 8c(8个约束): 性能,成本,时间,可靠性,安全性,合规性,技术型,兼容性
- 复杂度分析(高可用,高性能,可扩展)
- 备选方案(一般至少3个)
- 备选方案评估
架构设计模版(备选方案中选中一个)
- 总体方案
- 架构总览
- 核心流程
- 详细设计
- 安全设计
- 其他设计
- 部署方案
- 架构演进规划
51 架构师成长之路
- 内功: 执行力,判断力,创新力
- 路径(架构师)
- 工程师(1-3年): 在指导下完成开发;基础积累
- 高级工程师(2-5): 独立完成开发;积累方案设计经验
- 技术专家(4-8): 某个领域(包括语言、框架、数据库)的专家; 拓展宽度
- 初级架构师(5-10): 独立完成一个系统的架构设计;形成方法论
- 中级架构师(>8): 能完成复杂系统的架构设计;技术深度和理论的积累
- 高级架构师: 创造新的架构模式
番外3. 开源项目
开源项目的学习
- 谁都能从开源项目学到东西
- 不要太关注数据结构和算法
- 采用自上而下的方法,源码是最后一步(以下前三步应该是必备的)
- 安装、运行
- 从命令行参数和配置文件看原理
- 关键特性的原理研究
- 阅读设计/官方文档
- 网上的分析文档
- 自己写demo
- 用于生产环境需要测试,因为场景和别人测试的必然不一样
- 源码研究,可以通过demo的调用栈去理解基础库
开源项目的选择,使用,二次开发
- 原则: 不要重复造轮子,但要找到合适的
- 选择
- 是否满足业务(合适原则和演化原则)
- 是否成熟(版本号,活跃度,使用的公司数量)
- 运维能力(日志齐全、命令行等工具、故障检测)
- 使用
- 研究、测试
- 灰度发布,首先用于非核心业务
- 做好应急
- 二次开发
- 保持纯洁,加以包装(防止投入太大和跟随原项目的能力)
- 还是造轮子吧
番外4. 看书
每天挤时间坚持看书,可越看越快乃至一年50本书
技术类书学习原则(不同栈,不同语言各不相同)
- 代码运行环境如linux
- 核心工具如java
- 基础知识如网络、算法
- 成熟技术如mysql、框架
linux后端java工程师为例的书单(省略了人生类和业务类书籍)
- unix编程艺术
- unix网络编程
- unix环境高级编程
- linux系统编程
- TCP/IP详解
- 算法之美
- 算法设计与应用
- java编程思想(除了这两本java的,其他都是后端通用,但其实后端也应该看下java的)
- 深入理解java虚拟机
- C++ Primer(作者认为C++是后端必须要看看的)
